Imagine a student who can pass an exam on a subject they've never studied. How is this possible? The answer lies in humans' capacity for understanding and generalization. Humans can apply knowledge acquired in one context to new and unknown situations. This process of generalization and adaptation is fundamental to learning and intelligence. Now, think of an artificial intelligence capable of classifying concepts it has never seen in its training. Is it possible for an AI to perform this task? The answer is yes, and it's known as Zero-Shot Learning (ZSL). In this article, we'll explore how language models can perform text classifications without prior training in a specific domain.
Zero-Shot Text Classification
Zero-Shot Text Classification (ZSTC) is a machine learning technique that allows models to classify texts into categories without having been previously trained on those specific categories. It uses pre-trained language models, such as BART or Distil Roberta, which have learned to understand semantic relationships between words and phrases during their pre-training. This approach allows the model to generalize its knowledge and make inferences about new categories based on a given text, without the need for labeled examples (Wenpeng Yin et al, 2019, Paul Puri et al, 2019, Tassallah Abdullahi et al, 2024). This capability represents a significant advance over traditional supervised learning, where models need examples of each class to perform accurate classification.
The term "Zero-Shot" refers to the ability of a model to handle tasks or make predictions without specific prior training. In this approach, the model must leverage and transfer knowledge acquired during its training on other related tasks or categories to address these new categories not previously seen.
Zero-Shot classification is particularly useful in scenarios where:
- It's impractical or costly to label training examples for all categories.
- Categories change over time and it's difficult to maintain an updated training set.
- Rapid adaptation to new categories is required without the need to retrain the model.
Let's look at a practical example of how ZSTC can be implemented using pre-trained language models:
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli", device=0)
text = "The new restaurant in the city center offers a unique culinary experience, blending traditional flavors with modern techniques."
candidate_labels = ["Restaurant review", "Local news", "Cooking recipe", "Tourist guide"]
result = classifier(text, candidate_labels, multi_label=True)
print(f"Text: {text}")
print(f"Most likely label: {result['labels'][0]}")
print(f"Score: {result['scores'][0]:.4f}")
## Output
# The new restaurant in the city center offers a unique culinary experience, blending traditional flavors with modern techniques.
# Most likely label: Local news
# Score: 0.5561
In this example, we're using a pre-trained model to classify a text into categories it may not have seen before. Facebook's BART-large-mnli model is a pre-trained language model that has been fine-tuned on the ZSTC task. By providing the text and a list of candidate labels, the model returns the most likely label and the score associated with that prediction. In this case, the model classifies the text as "Local news" with a score of 0.5561.
There are many approaches to solving Zero-Shot classification problems: Latent Embeddings, Text Aware Representation of Sentence and Natural Language Inference. In this article, we'll focus on ZSTC based on Natural Language Inference (NLI). This approach uses pre-trained language models to infer the relationship between a premise (the input text) and a hypothesis (the description of a candidate category) to perform classification, as we'll see next.
How does NLI-based Zero-Shot classification work?
Natural Language Inference (NLI) is the task of determining whether a statement (hypothesis) is true, false, or neutral given a premise. This concept can be ingeniously adapted to Zero-Shot classification tasks, allowing us to classify texts into categories without the need for prior training in those specific categories.
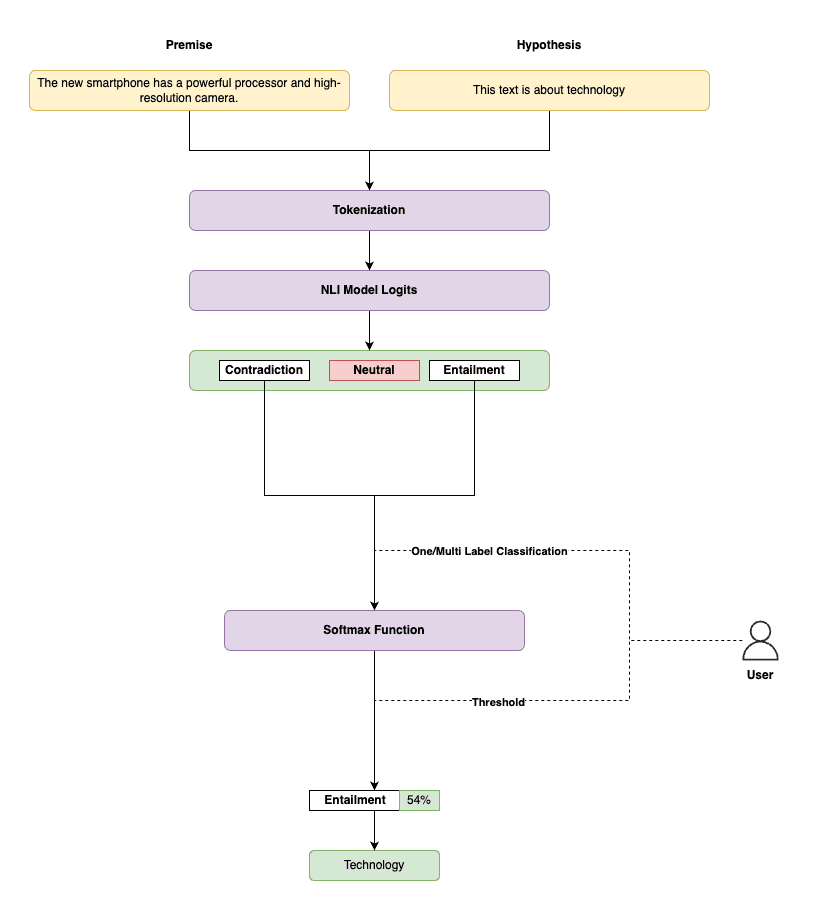
Figure 1. NLI-based Zero-Shot classification architecture.
In this approach, we treat the premise as the input text we want to classify, and the hypothesis as the description of a candidate category. For example, if we want to classify a text in the "Technology" category, we can formulate the task as follows:
- Premise: "The new smartphone has a powerful processor and a high-resolution camera."
- Hypothesis: "This text is about technology."
The NLI model will evaluate the relationship between the premise and the hypothesis to determine if the text belongs to the technology category. This process is repeated for each candidate category we want to consider.
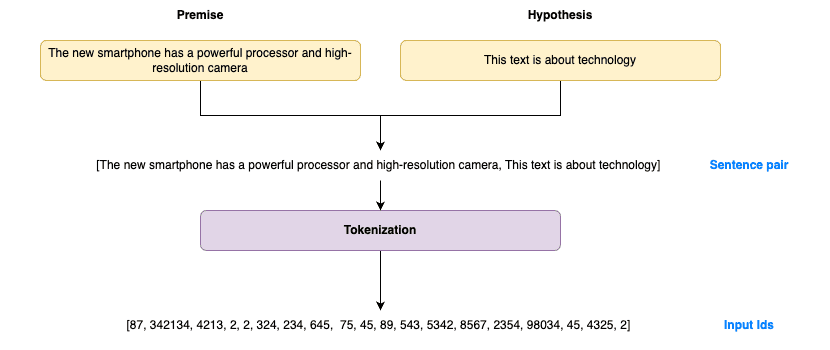
Figure 2. Tokenization process in Zero-Shot classification.
The process begins with tokenization, where the input text (premise) and the category description (hypothesis) are converted into a sequence of tokens that the model can process. As shown in Figure 2, this sequence of tokens is represented as a pair of sentences which are then converted into a series of input IDs that the model will use.
Once we have the input IDs, the NLI model processes them to generate logits (scores). These logits represent the raw scores for each possible class (contradiction, neutrality, or entailment) in the NLI task.
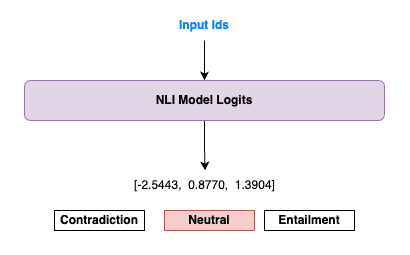
Figure 3. Logits generated by the NLI model.
As shown in Figure 3, the model produces a set of logits for each premise-hypothesis pair. In this case, we see that the highest logit corresponds to the entailment class, suggesting that the input text is strongly related to the category proposed in the hypothesis.
For multi-class or multi-label classification cases, we repeat this process for each candidate category.
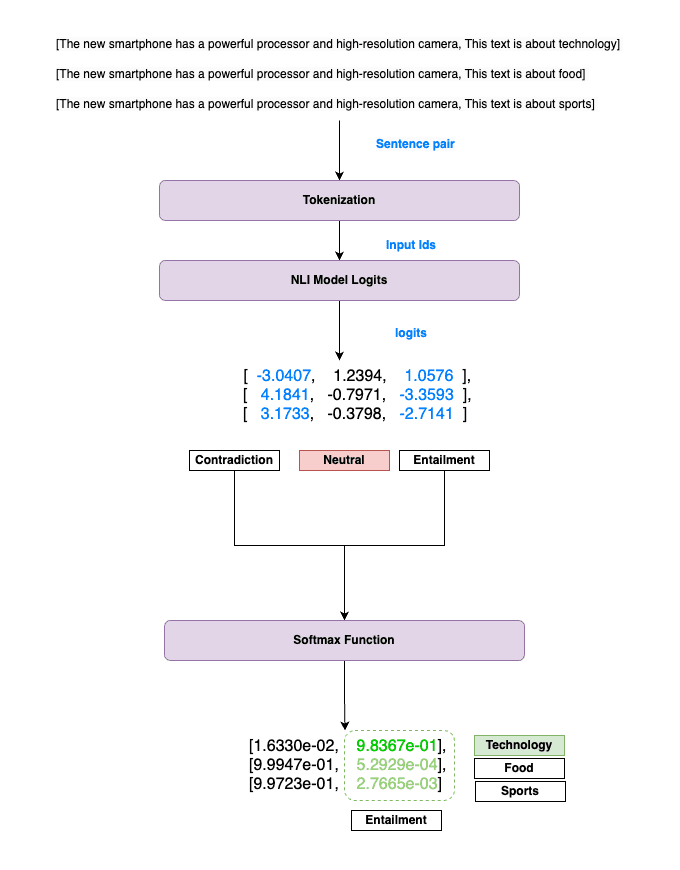
Figure 4. Multi-class Zero-Shot classification process.
Figure 4 illustrates how multi-class classification is handled. The same input text is paired with multiple hypotheses, one for each candidate category. The model generates logits for each pair, and then we apply the softmax function to these logits to obtain normalized probabilities for each category.
Mathematically, the probability that the text belongs to a specific category is calculated using the softmax function:
Where is the logit associated with category and is the total number of categories. The softmax function normalizes the logits to obtain a probability distribution over the candidate labels.
In Python, we can implement Zero-Shot classification using the transformers library from Hugging Face, which provides a simple interface for working with pre-trained language models. Below is an example of how to implement Zero-Shot classification in Python using Facebook's BART-large-mnli model:
import numpy as np
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
# Load pre-trained model and tokenizer
model = AutoModelForSequenceClassification.from_pretrained("facebook/bart-large-mnli")
tokenizer = AutoTokenizer.from_pretrained("facebook/bart-large-mnli")
def zero_shot_classify(text, labels):
# Create hypotheses based on candidate labels
hypothesis = [f"This text is about {label}." for label in labels]
premise = [text] * len(labels)
# Tokenize inputs (premise and hypothesis) for the model
inputs = tokenizer(premise, hypothesis, return_tensors="pt", padding=True, truncation=True)
# Generate predictions with the model
with torch.no_grad(): # Disable gradient calculation for inference
logits = model(**inputs).logits[:, [0, 2]]
probs = logits.softmax(dim=1)
# Extract probabilities corresponding to the positive label (index 1)
label_probs = probs[:, 1]
return dict(zip(labels, label_probs.tolist()))
# Input text and candidate labels
text = "The new smartphone has a powerful processor and high-resolution camera."
labels = ["technology", "food", "sports"]
# Zero-Shot Classification
results = zero_shot_classify(text, labels)
print(results)
## Output
# {'technology': 0.9836695194244385, 'food': 0.0005292915157042444, 'sports': 0.0027664615772664547}
Advantages of ZSTC
ZSTC offers several advantages over traditional classification approaches, especially in scenarios where the availability of labeled data is limited or costly. Let's look at some of the key advantages of this approach.
Flexibility and adaptability
Zero-Shot models, by using pre-trained language models, can quickly adapt to new categories or tasks without the need for additional training. This allows for greater flexibility and adaptability in environments where categories change frequently or where it's difficult to obtain training examples for all categories. A practical example can be seen below, where new labels are added without the need to adjust the model:
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli", device=0)
# Existing texts and labels
texts = ["The new AI algorithm outperforms humans in chess",
"The latest operating system update improves security"]
labels = ["artificial intelligence", "software"]
# New text and label
new_text = "The 3D printer creates custom prosthetics for patients"
new_label = "medical technology"
# Zero-Shot classification with the new label
all_labels = labels + [new_label]
for text in texts + [new_text]:
result = classifier(text, all_labels, multi_label=True)
print(f"Text: {text}")
print(f"Classification: {result['labels'][0]}")
print(f"Confidence: {result['scores'][0]:.2f}\n")
## Output
# Text: The new AI algorithm outperforms humans in chess
# Classification: artificial intelligence
# Confidence: 0.77
# Text: The latest operating system update improves security
# Classification: software
# Confidence: 0.99
# Text: The 3D printer creates custom prosthetics for patients
# Classification: medical technology
#Confidence: 0.99
In this example, we can see how the model is able to correctly classify a text in a new previously unseen category, "medical technology", with high confidence.
Reduction in the need for labeled data
In many real-world scenarios, some classes may have very few training examples. Zero-Shot classification shines in these situations:
- Allows classification in rare or underrepresented categories
- Useful in specialized domains where data collection is costly or difficult
Efficiency in resources and time
Zero-Shot classification eliminates the need to collect and label large amounts of training data for each category. This saves time and resources by avoiding the process of collecting, cleaning, and labeling data, and allows for rapid adaptation to new categories without the need to retrain the model.
Scalability to a large number of categories
Traditional classification methods can be limited in the number of categories they can handle. Zero-Shot classification handles this problem elegantly:
- Can potentially handle an unlimited number of categories
- Does not suffer from class imbalances, as it does not require a balanced training set
Knowledge transfer between domains
Zero-Shot classification allows for a form of knowledge transfer between domains:
- Uses the general knowledge of the pre-trained language model to infer about new domains
- Can adapt knowledge from one domain to a related one
Example of knowledge transfer between domains:
# Classification in a new domain
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli", device=0)
tech_text = "The new smartphone features a high-resolution OLED display"
medical_text = "The patient exhibits symptoms of acute bronchitis"
diverse_labels = ["technology", "medicine", "sports", "cooking"]
for text in [tech_text, medical_text]:
result = classifier(text, diverse_labels)
print(f"Text: {text}")
print(f"Classification: {result['labels'][0]}")
print(f"Confidence: {result['scores'][0]:.2f}\n")
## Output
# Text: The new smartphone features a high-resolution OLED display
# Classification: technology
# Confidence: 0.99
# Text: The patient exhibits symptoms of acute bronchitis
# Classification: medicine
# Confidence: 0.89
Flexibility in class formulation
Zero-Shot classification allows great flexibility in how classes are formulated:
- Classes can be described with phrases or even complete sentences.
- Allows for more nuanced and contextual classification.
# Classification with detailed class descriptions
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli", device=0)
text = "The company announced record profits this quarter"
detailed_labels = [
"Financial news about corporate performance",
"Technology advancements in the business sector",
"Environmental impact of corporate activities"
]
result = classifier(text, detailed_labels)
print(f"Text: {text}")
print(f"Classification: {result['labels'][0]}")
print(f"Confidence: {result['scores'][0]:.2f}")
## Output
# Text: The company announced record profits this quarter
# Classification: Financial news about corporate performance
# Confidence: 0.99
Handling multiple labels
Language models allow ZSTC with multiple labels, that is, the possibility of assigning more than one label to a text. This is useful in scenarios where a text can belong to several categories simultaneously.
Let's look at a practical example of how this can be implemented:
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli", device=0)
text = "The new smartphone features a high-resolution camera, 5G connectivity, and a powerful AI chip."
labels = ["camera quality", "network technology", "processing power", "battery life"]
result = classifier(text, labels, multi_label=True)
print("Text:", text)
print("\nMulti-label classification results:")
for label, score in zip(result['labels'], result['scores']):
if score > 0.5: # Adjust this threshold as needed
print(f"{label}: {score:.2f}")
## Output
# Text: The new smartphone features a high-resolution camera, 5G connectivity, and a powerful AI chip.
# Multi-label classification results:
# camera quality: 0.94
# processing power: 0.78
The ability to handle multiple labels significantly expands the applicability of ZSTC in real-world scenarios, where complexity and multidimensionality are the norm rather than the exception.
Best practices
Zero-Shot classification, although powerful and versatile, requires a careful approach to maximize its effectiveness. I want to point out some best practices to keep in mind when working with this approach:
Handling ambiguity
As we've seen, pre-trained language models can be very good at inferring context and semantic relationships in a text. However, they may have difficulties with ambiguous texts or those with multiple interpretations. It's important to consider ambiguity and uncertainty in the model's predictions and consider how to handle them in your application. When multiple labels seem equally likely, it's crucial to analyze the confidence scores and consider the context.
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli", device=0)
ambiguous_text = "The bank by the river was crowded."
labels = ["financial institution", "river bank", "crowded place"]
result = classifier(ambiguous_text, labels)
print("Text:", ambiguous_text)
print("\nClassification results:")
for label, score in zip(result['labels'], result['scores']):
print(f"{label}: {score:.2f}")
print("\nAnalysis:")
if max(result['scores']) - min(result['scores']) < 0.1:
print("This case is ambiguous. Consider providing more context or refining the labels.")
else:
print(f"The most likely interpretation is: {result['labels'][0]}")
## Output
# Text: The bank by the river was crowded.
# Classification results:
# crowded place: 0.50
# river bank: 0.50
# financial institution: 0.00
# Analysis:
# The most likely interpretation is: crowded place
In the above example, we've set a threshold difference of 0.1 to identify ambiguous cases. When ambiguity is detected in the predictions, consider providing more context or refining the labels to improve classification accuracy. And in critical applications, implement a human review system for ambiguous cases.
Careful label selection
The choice of labels can have a significant impact on model performance:
- Use clear and mutually exclusive labels when possible.
- Avoid labels that are too general or too specific.
- Consider multiple formulations of the same label to capture different nuances.
good_labels = ["technology news", "sports report", "financial analysis"]
poor_labels = ["news", "report", "article"] # Too broad
Text preprocessing
Proper preprocessing can improve classification accuracy:
- Remove irrelevant information or noise from the input text.
- Normalize the text (lowercase, punctuation removal, etc.).
- Consider expanding acronyms or domain-specific terms.
Use of prompt engineering
The way you formulate the task can affect the model's performance:
# Standard approach
result = classifier(text, labels)
# With prompt engineering
hypothesis_template = "This text is about {}."
result = classifier(text, labels, hypothesis_template=hypothesis_template)
Validation and adjustment
Implement a continuous validation process:
- Use a test dataset to regularly evaluate performance.
- Adjust labels and the model as necessary.
- Consider fine-tuning the base model if sufficient domain-specific data is available.
Handling low confidence cases
Implement strategies to handle low confidence predictions:
confidence_threshold = 0.5
result = classifier(text, labels)
if max(result['scores']) < confidence_threshold:
print("Low confidence prediction. Consider manual review.")
Use cases
Zero-Shot classification has a wide range of applications in various industries and fields. Let's look at some examples:
- Email classification in a corporate environment:
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli", device=0)
def classify_email(email_body):
labels = ["Urgent", "Sales Lead", "Technical Support", "HR Related", "General Inquiry"]
confidence_threshold = 0.6
result = classifier(email_body, labels)
top_label = result['labels'][0]
top_score = result['scores'][0]
if top_score < confidence_threshold:
return "Needs Human Review", top_score
else:
return top_label, top_score
# Usage examples
email_body = "We need to schedule an urgent meeting to discuss the Q3 financial reports."
category, confidence = classify_email(email_body)
print(f"Email Category: {category}")
print(f"Confidence: {confidence:.2f}")
if category == "Needs Human Review":
print("This email requires manual classification.")
else:
print(f"Automated action: Route to {category} department")
## Output
# Email Category: Urgent
# Confidence: 0.94
# Automated action: Route to Urgent department
- Sentiment analysis in product reviews:
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli", device=0)
def analyze_product_review(review):
labels = ["Positive", "Negative", "Neutral"]
aspect_labels = ["Quality", "Price", "Customer Service", "Usability"]
confidence_threshold = 0.7
sentiment_result = classifier(review, labels)
aspect_result = classifier(review, aspect_labels, multi_label=True)
sentiment = sentiment_result['labels'][0]
sentiment_score = sentiment_result['scores'][0]
if sentiment_score < confidence_threshold:
sentiment = "Ambiguous"
aspects = [label for label, score in zip(aspect_result['labels'], aspect_result['scores']) if score > 0.5]
return sentiment, aspects
# Usage example
review = "The product is well-made but a bit overpriced. The customer support was helpful when I had questions."
sentiment, aspects = analyze_product_review(review)
print(f"Overall Sentiment: {sentiment}")
print(f"Aspects Mentioned: {', '.join(aspects)}")
if sentiment == "Ambiguous":
print("This review needs further analysis for accurate sentiment classification.")
## Output
# Overall Sentiment: Ambiguous
# Aspects Mentioned: Quality, Price, Customer Service
# This review needs further analysis for accurate sentiment classification.
- News classifier for a content aggregator:
from transformers import pipeline
import numpy as np
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli", device=0)
def categorize_news_article(article_text):
main_categories = ["Politics", "Technology", "Sports", "Entertainment", "Business", "Science"]
sub_categories = {
"Politics": ["Domestic", "International", "Election", "Policy"],
"Technology": ["AI", "Cybersecurity", "Gadgets", "Internet"],
"Sports": ["Football", "Basketball", "Tennis", "Olympics"],
"Entertainment": ["Movies", "Music", "Celebrity", "TV Shows"],
"Business": ["Stock Market", "Startups", "Economy", "Corporate"],
"Science": ["Space", "Climate", "Medicine", "Biology"]
}
confidence_threshold = 0.4
# Main category classification
main_result = classifier(article_text, main_categories)
main_category = main_result['labels'][0]
main_score = main_result['scores'][0]
if main_score < confidence_threshold:
return "Uncategorized", [], main_score
# Sub-category classification
sub_result = classifier(article_text, sub_categories[main_category])
sub_category = sub_result['labels'][0]
sub_score = sub_result['scores'][0]
# Calculate average confidence
avg_confidence = np.mean([main_score, sub_score])
if avg_confidence < confidence_threshold:
return main_category, [], avg_confidence
else:
return main_category, [sub_category], avg_confidence
# Usage example
article = """
SpaceX successfully launched its latest batch of Starlink satellites into orbit on Monday.
The mission, which took off from Cape Canaveral, Florida, deployed 60 new satellites,
expanding the company's growing constellation of broadband internet satellites.
"""
main_category, sub_categories, confidence = categorize_news_article(article)
print(f"Main Category: {main_category}")
if sub_categories:
print(f"Sub-Category: {sub_categories[0]}")
print(f"Confidence: {confidence:.2f}")
if confidence < 0.4:
print("This article needs manual review for accurate categorization.")
elif not sub_categories:
print("Could not determine a specific sub-category. Consider refining the classification.")
## Output
# Main Category: Uncategorized
# Confidence: 0.33
# This article needs manual review for accurate categorization.
It's also possible to combine Zero-Shot with other NLP methods to improve results, such as entity extraction, intent classification, or text generation.
- Financial news analysis
from transformers import pipeline
# Initialize models
zero_shot_classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli")
ner_pipeline = pipeline("ner", model="dbmdz/bert-large-cased-finetuned-conll03-english")
def analyze_financial_news(text):
# Categories for Zero-Shot
categories = ["Stock Market", "Mergers and Acquisitions", "Earnings Report", "Economic Policy"]
# Perform Zero-Shot Classification
zs_result = zero_shot_classifier(text, categories)
# Perform NER
ner_result = ner_pipeline(text)
# Extract relevant entities
companies = set([entity['word'] for entity in ner_result if entity['entity'] == 'I-ORG'])
# Combine results
confidence_threshold = 0.5
top_category = zs_result['labels'][0]
confidence = zs_result['scores'][0]
if confidence < confidence_threshold:
print("Low confidence prediction. Consider manual review.")
return None, companies
return top_category, companies
# Usage example
news_text = "Apple Inc. reported record-breaking quarterly earnings, exceeding Wall Street expectations. The tech giant's stock surged in after-hours trading."
category, mentioned_companies = analyze_financial_news(news_text)
if category:
print(f"News Category: {category}")
print(f"Mentioned Companies: {', '.join(mentioned_companies)}")
## Output
# News Category: Earnings Report
# Mentioned Companies: Apple, Inc
- Tweet classification with user context
from transformers import pipeline
zero_shot_classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli")
ner_pipeline = pipeline("ner", model="dbmdz/bert-large-cased-finetuned-conll03-english")
def classify_tweet_with_context(tweet, user_bio):
# Categories for Zero-Shot
categories = ["Technology", "Politics", "Entertainment", "Sports", "Science"]
# Perform Zero-Shot Classification on the tweet
zs_result = zero_shot_classifier(tweet, categories)
# Perform NER on user's bio
ner_result = ner_pipeline(user_bio)
# Extract relevant entities from the bio
user_interests = set([entity['word'] for entity in ner_result if entity['entity'] in ['I-ORG', 'I-MISC']])
# Combine results
confidence_threshold = 0.5
top_category = zs_result['labels'][0]
confidence = zs_result['scores'][0]
if confidence < confidence_threshold:
# If confidence is low, use user's bio to infer category
for interest in user_interests:
interest_result = zero_shot_classifier(interest, categories)
if interest_result['scores'][0] > confidence:
top_category = interest_result['labels'][0]
confidence = interest_result['scores'][0]
if confidence < confidence_threshold:
print("Low confidence prediction. Consider manual review.")
return None
return top_category
# Usage example
tweet = "Just watched the latest episode. Mind blown!"
user_bio = "Tech enthusiast. AI researcher at Google. Avid sci-fi reader."
category = classify_tweet_with_context(tweet, user_bio)
if category:
print(f"Tweet Category: {category}")
## Output
# Tweet Category: Entertainment
Evaluation and metrics
Evaluating the performance of Zero-Shot classification models is crucial to understand their effectiveness and limitations. Unlike traditional methods, these models are tested on categories not seen during training, which requires a specific evaluation approach. To illustrate this process, we will use the AG News dataset, which contains news from four categories: World, Sports, Business, and Sci/Tech. We will implement a Zero-Shot classifier using the BART-large-mnli model and evaluate its performance with various metrics.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from transformers import pipeline
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from sklearn.model_selection import train_test_split
from tqdm import tqdm
# Load the AG News dataset
def load_ag_news():
train_data = pd.read_csv('https://raw.githubusercontent.com/mhjabreel/CharCnn_Keras/master/data/ag_news_csv/train.csv', header=None)
test_data = pd.read_csv('https://raw.githubusercontent.com/mhjabreel/CharCnn_Keras/master/data/ag_news_csv/test.csv', header=None)
data = pd.concat([train_data, test_data], axis=0)
data.columns = ['Class', 'Title', 'Content']
data['Text'] = data['Title'] + " " + data['Content']
return data
# Load and prepare the data
data = load_ag_news()
class_mapping = {1: "World", 2: "Sports", 3: "Business", 4: "Sci/Tech"}
data['Class'] = data['Class'].map(class_mapping)
# Take a random sample to reduce processing time
sample_size = 1000 # Adjust this number according to your processing capacity
data_sample = data.sample(n=sample_size, random_state=42)
# Split into training and test sets
train_data, test_data = train_test_split(data_sample, test_size=0.2, random_state=42)
# Prepare the Zero-Shot classifier
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli", device=0)
# Function to evaluate the classifier
def evaluate_zero_shot_classifier(test_data, all_labels):
true_labels = []
predicted_labels = []
confidences = []
for _, row in tqdm(test_data.iterrows(), total=len(test_data)):
result = classifier(row['Text'], all_labels)
predicted_label = result['labels'][0]
true_labels.append(row['Class'])
predicted_labels.append(predicted_label)
confidences.append(result['scores'][0])
return true_labels, predicted_labels, confidences
# Evaluate the classifier
all_labels = list(class_mapping.values())
true_labels, predicted_labels, confidences = evaluate_zero_shot_classifier(test_data, all_labels)
# Calculate metrics
accuracy = accuracy_score(true_labels, predicted_labels)
print(f"Overall accuracy: {accuracy:.2f}")
print("\nClassification Report:")
print(classification_report(true_labels, predicted_labels, target_names=all_labels))
# Visualize the confusion matrix
cm = confusion_matrix(true_labels, predicted_labels, labels=all_labels)
plt.figure(figsize=(10, 8))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=all_labels, yticklabels=all_labels)
plt.title('Confusion Matrix')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.show()
# Visualize the confidence distribution
plt.figure(figsize=(10, 6))
sns.histplot(confidences, kde=True)
plt.title('Distribution of Confidence Scores')
plt.xlabel('Confidence')
plt.ylabel('Count')
plt.show()
# Calculate additional statistics
mean_confidence = np.mean(confidences)
median_confidence = np.median(confidences)
std_confidence = np.std(confidences)
print(f"\nMean Confidence: {mean_confidence:.2f}")
print(f"Median Confidence: {median_confidence:.2f}")
print(f"Standard Deviation of Confidence: {std_confidence:.2f}")
# Calculate per-class accuracy
per_class_accuracy = {}
for label in all_labels:
mask = np.array(true_labels) == label
per_class_accuracy[label] = accuracy_score(np.array(true_labels)[mask], np.array(predicted_labels)[mask])
print("\nPer-Class Accuracy:")
for label, acc in per_class_accuracy.items():
print(f"{label}: {acc:.2f}")
# Visualize per-class accuracy
plt.figure(figsize=(12, 6))
sns.barplot(x=list(per_class_accuracy.keys()), y=list(per_class_accuracy.values()))
plt.title('Per-Class Accuracy')
plt.xlabel('Class')
plt.ylabel('Accuracy')
plt.xticks(rotation=45)
plt.show()
This code evaluates the Zero-Shot classifier using standard metrics such as precision, recall, and F1-score. Additionally, it generates visualizations like the confusion matrix and the distribution of confidence scores, providing insights into the model's performance across different categories and its level of certainty in predictions.
Evaluation on a real dataset like AG News allows for a deeper understanding of how the model behaves in practical scenarios, revealing its strengths and areas for improvement in text classification without specific training.
The results are shown below:
## Output
Overall accuracy: 0.74
Classification Report:
precision recall f1-score support
World 0.62 0.70 0.65 46
Sports 0.76 0.51 0.61 51
Business 0.93 0.94 0.94 54
Sci/Tech 0.68 0.82 0.74 49
accuracy 0.74 200
macro avg 0.75 0.74 0.74 200
weighted avg 0.75 0.74 0.74 200
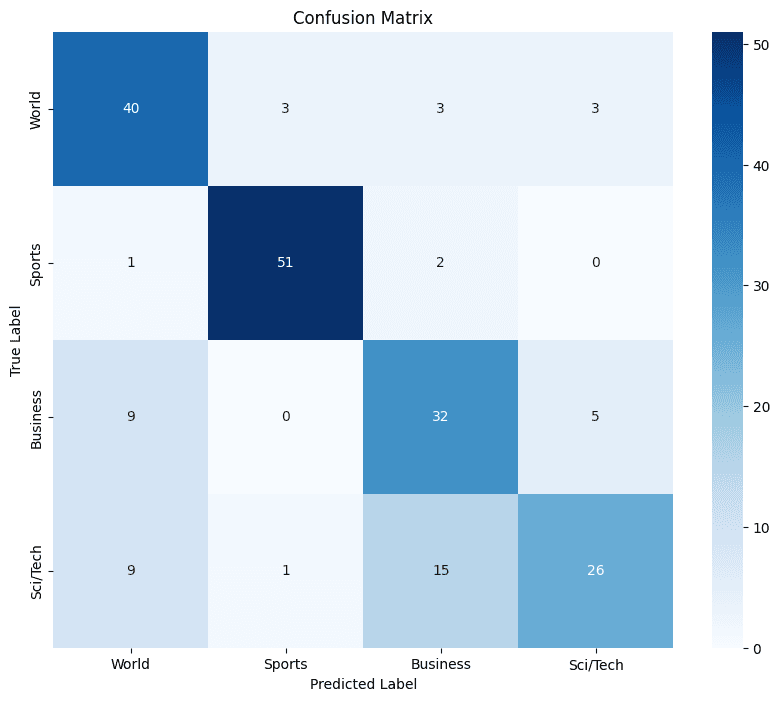
Figure 5. Confusion matrix showing the distribution of correct and incorrect predictions across different categories.
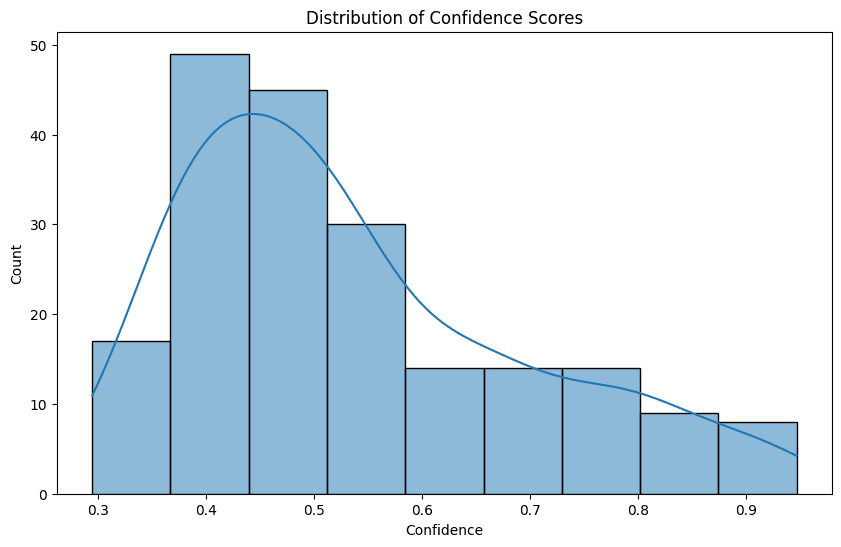
Figure 6. Distribution of confidence scores for the Zero-Shot classifier's predictions.
Mean Confidence: 0.54
Median Confidence: 0.50
Standard Deviation of Confidence: 0.16
Per-Class Accuracy:
World: 0.82
Sports: 0.94
Business: 0.70
Sci/Tech: 0.51
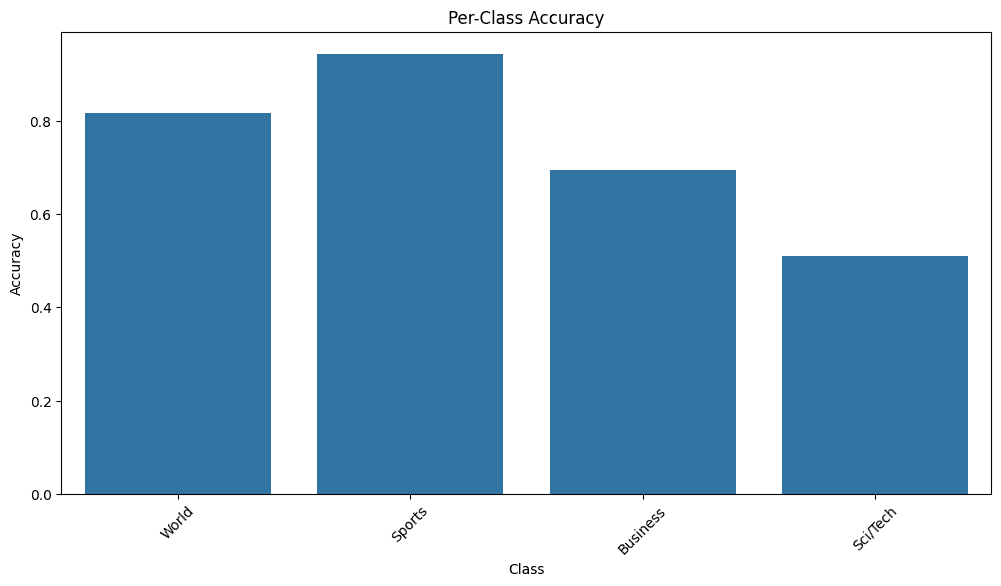
Figure 7. Per-class accuracy in Zero-Shot classification of AG News.
The classification report shows varied performance of the Zero-Shot model across different categories in the AG News dataset. The overall accuracy of the model is 74%, which is quite good for a Zero-Shot approach. The "Business" category stands out with excellent performance (F1-score of 0.94), suggesting that the model identifies this type of content very well. "Sci/Tech" also shows good performance (F1-score of 0.74). However, the model seems to have more difficulties with "World" and "Sports", with F1-scores of 0.65 and 0.61 respectively. This could indicate that these categories are more challenging to distinguish or that their semantic features are less distinctive for the model. Overall, the classifier shows promising performance, especially considering that it was not specifically trained on this dataset.
Limitations and considerations
Although Zero-Shot classification is powerful, it has its limitations. The model's performance depends on the quality of pre-training and the semantic relationship between the input and the labels. It may have difficulties with highly specialized domains or concepts far from its training data. It's always important to validate the results and consider fine-tuning for specific use cases.
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="facebook/bart-large-mnli", device=0)
# Example of a limitation: highly specialized domain
specialized_text = "The patient exhibits signs of keratoconus in the left eye."
general_labels = ["health", "sports", "technology"]
specialized_labels = ["ophthalmology", "cardiology", "neurology"]
print("General labels:")
print(classifier(specialized_text, general_labels))
print("\nSpecialized labels:")
print(classifier(specialized_text, specialized_labels))
# Example of a concept far from training data
unusual_text = "The zorblax fluttered its tentacles in the crimson sky of Xargon-7."
labels = ["science fiction", "historical fiction", "romance", "mystery"]
print("\nUnusual concept:")
print(classifier(unusual_text, labels))
## Output
# General labels:
# {'sequence': 'The patient exhibits signs of keratoconus in the left eye.', 'labels': ['health', 'technology', 'sports'], 'scores': [0.7707374095916748, 0.135053813457489, 0.0942087471485138]}
#Specialized labels:
# {'sequence': 'The patient exhibits signs of keratoconus in the left eye.', 'labels': ['ophthalmology', 'neurology', 'cardiology'], 'scores': [0.9111181497573853, 0.06408613175153732, 0.02479572966694832]}
# Unusual concept:
# {'sequence': 'The zorblax fluttered its tentacles in the crimson sky of Xargon-7.', 'labels': ['science fiction', 'mystery', 'historical fiction', 'romance'], 'scores': [0.48209530115127563, 0.2437402755022049, 0.16008099913597107, 0.11408346891403198]}
Additional points to consider:
Sensitivity to formulation: Performance can vary significantly depending on how class labels are formulated.
Model bias: Pre-trained models may reflect biases present in their training data.
Context limitations: They may have difficulties with tasks that require extensive contextual knowledge or complex reasoning.
Scalability: Inference time may increase with the number of potential classes.
Interpretability: It can be difficult to understand exactly how the model arrives at its decisions.
It is crucial to conduct a thorough evaluation in the specific domain of application and consider these limitations when implementing solutions based on Zero-Shot classification.
Conclusions
ZSTC offers a transformative approach to textual data categorization, especially in scenarios where labeled data is scarce or costly to obtain. By leveraging knowledge embedded in pre-trained language models, ZSTC can generalize to new categories and domains without the need for explicit training examples. This capability opens up a world of possibilities for automating tasks such as email routing, sentiment analysis, news categorization, and financial news analysis.
However, one aspect that has not been considered in this analysis is the consumption of computational resources, such as GPU usage, which can be significant in Zero-Shot classification. Although ZSTC offers advantages in terms of time and labeling savings, the computational cost remains a factor to consider, especially for large models that require specialized hardware to run inferences efficiently. Resource consumption can be decisive when choosing ZSTC over other methods, and remains an aspect that could influence certain applications and environments where resources are limited or costly.
The flexibility of ZSTC allows for rapid adaptation to evolving categories and the incorporation of nuanced class descriptions, making it highly versatile for real-world applications. Additionally, it reduces dependence on large labeled datasets, saving time and resources, while allowing scaling to a large number of categories.
However, it is crucial to recognize the limitations of ZSTC. The model's performance heavily depends on the quality of its pre-training data and the semantic relationship between the input text and the provided labels. Ambiguity in the text, highly specialized domains, and concepts far from the model's training data can present challenges.
To maximize the effectiveness of ZSTC, special attention should be paid to label selection, text preprocessing, and prompt design. Implementing a robust validation process, handling low-confidence predictions, and addressing potential biases in the model are essential for reliable implementations. As ZSTC continues to advance, a deep understanding of its capabilities, limitations, and ethical implications will be fundamental to harnessing its full potential in various text-based applications.
Finally, if there are any errors, omissions, or inaccuracies in this article, please do not hesitate to contact us through the following Discord channel: Math & Code.
