
Escrito por Alejandro Sánchez Yalí con Jenalee Prentice. Publicado originalmente el 2024-07-03 en el blog de Monadical.
Introducción
Hay una nueva generación de avatares en escena, comúnmente conocidos como humanos digitales o avatares de IA1. Estos avatares han ganado este nombre algo serio porque simulan la apariencia y el comportamiento humano de una manera notablemente realista. Por ejemplo, a menudo están diseñados con rasgos imperfectos, como un tono de piel desigual o una cara asimétrica. También imitan las habilidades de lenguaje natural de los humanos simulando movimientos y señales no verbales a través del análisis de sentimientos generado por LLM (Large Language Models)2.
Durante 2023, la convergencia de tecnologías de modelado 2D y 3D con herramientas de IA como Redes Generativas Antagónicas (GANs), Texto a Voz (TTS), Voz a Texto (STT) y LLMs trajo estos avatares a nuestras vidas, potencialmente redefiniendo nuestra interacción con las computadoras.
Tomemos, por ejemplo, Victoria Shi, la ministra digital ucraniana de asuntos exteriores, que ahorra tiempo y recursos a Ucrania proporcionando actualizaciones esenciales sobre asuntos consulares. O los avatares de IA utilizados por empresas para interactuar con clientes en diversas industrias como consultoría financiera, apoyo educativo, participación en los medios, videojuegos, y salud y bienestar.
Visión general del tutorial
Para entender mejor el potencial de los avatares de IA, este tutorial te enseñará cómo construir uno de A a Z. Ya seas un apasionado gamer, un emprendedor en busca de innovación o un futuro inversor en avatares de IA, este tutorial te proporcionará todas las herramientas que necesitas para crear y entender cómo funcionan estos fascinantes avatares digitales.
En mi tutorial anterior, El código Kraken: cómo construir un ai-avatar parlante, expliqué cómo implementar un ai-avatar parlante en 2D. Esta vez, subiremos la apuesta y aprenderemos cómo implementar un avatar de IA parlante en 3D con características mejoradas.
El código final de este tutorial se puede encontrar en este repositorio: Humano Digital.
Elementos clave de nuestro avatar de IA
Al final de este tutorial, habremos creado un avatar de IA que destaca entre sus contrapartes. Esto se logrará utilizando modelos GLTF, Mixamo y LLMs para animar y mejorar la sincronización labial y las habilidades de comunicación de nuestro avatar. En otras palabras, nuestro objetivo es construir un avatar que se vea y suene como un humano al conversar. Veamos las características específicas que incorporaremos en nuestro avatar para alcanzar este objetivo:
Apariencia hiperrealista: Los avatares de IA se están volviendo cada vez más realistas. Aunque a menudo se crean en un estudio y luego se sintetizan utilizando programas de aprendizaje automático, cada vez es más fácil y rápido crear avatares digitales utilizando solo modelos GLTF, fotos o videos grabados por uno mismo (ver editor Meshcapade). Para nuestro tutorial, utilizaremos un avatar en formato GLTF generado por Ready Player Me renderizado a través de React.js con React Three Fiber.
Movimientos corporales naturales: Para generar algunos movimientos corporales del avatar, utilizaremos Mixamo. En cuanto a sincronizar la voz con movimientos de boca suaves y naturales, utilizaremos Rhubarb lip-sync. Es un CLI que genera fonemas localmente, y luego lo usamos para sincronizar los movimientos de la boca con la voz.
Texto a voz (TTS): La tecnología de texto a voz (TTS) ha avanzado mucho desde los primeros días de asistentes de voz como el Agente de Microsoft y DECtalk en la década de 1990. Hoy en día, TTS puede producir voces realistas en todos los idiomas. Se puede utilizar esta tecnología para generar un habla convincente y natural si se combina con sincronización labial. En este caso, utilizaremos ElevenLabs, un servicio de texto a voz multilingüe.
Voz a texto (STT): El reconocimiento de voz es una característica crítica que permite a los usuarios interactuar con avatares digitales a través de comandos de voz. Para esto, utilizaremos Whisper, una API de Voz a Texto (STT) de OpenAI. Este sistema transforma la voz del usuario en texto para que la IA pueda escucharla adecuadamente.
Procesamiento y comprensión de información: Al aprovechar los modelos de lenguaje grande (LLMs) como GPT-4, podemos mejorar la capacidad del avatar de IA para procesar y comprender información. Los LLMs están entrenados con grandes cantidades de datos y pueden proporcionar respuestas contextualmente relevantes, mejorando la interacción entre los usuarios y los avatares digitales.
Latencia de respuesta: La interacción entre humanos y avatares de IA aún no es tan fluida como una interacción humana real. En este caso, nuestro avatar todavía tendrá alta latencia, una característica que mejoraremos en un futuro post.
Configuración del proyecto
La arquitectura de nuestro sistema tiene dos directorios: el directorio frontend, que se encarga de renderizar el avatar, y el directorio backend, que es responsable de coordinar todos los servicios de inteligencia artificial.
digital-human
├── backend
└── frontend
Comenzamos desarrollando un proyecto React desde cero dentro del directorio frontend, utilizando Tailwind CSS y Vite como soporte. Asumimos que el lector tiene experiencia previa con React. Sin embargo, si necesitas orientación sobre cómo iniciar un proyecto con React, Tailwind CSS y Vite, te sugerimos consultar el siguiente post: Cómo Configurar Tailwind CSS en React JS con VS Code.
Después de instalar el proyecto React, actualiza la estructura para que se parezca a la siguiente:
├── index.html
├── package.json
├── postcss.config.js
├── public
│ ├── animations
│ │ ├── angry.fbx
│ │ ├── defeated.fbx
│ │ ├── dismissing_gesture.fbx
│ │ ├── happy_idle.fbx
│ │ ├── idle.fbx
│ │ ├── sad_idle.fbx
│ │ ├── surprised.fbx
│ │ ├── talking.fbx
│ │ ├── talking_one.fbx
│ │ ├── talking_two.fbx
│ │ └── thoughtful_head_shake.fbx
│ ├── favicon.ico
│ ├── models
│ │ ├── animations.glb
│ │ ├── animations.gltf
│ │ ├── animations_data.bin
│ │ ├── avatar.fbm
│ │ ├── avatar.fbx
│ │ └── avatar.glb
│ └── vite.svg
├── src
│ ├── App.jsx
│ ├── components
│ │ ├── Avatar.jsx
│ │ ├── ChatInterface.jsx
│ │ └── Scenario.jsx
│ ├── constants
│ │ ├── facialExpressions.js
│ │ ├── morphTargets.js
│ │ └── visemesMapping.js
│ ├── hooks
│ │ └── useSpeech.jsx
│ ├── index.css
│ └── main.jsx
├── tailwind.config.js
├── vite.config.js
└── yarn.lock
E instalamos las siguientes dependencias:
$ yarn add three
$ yarn add @types/three
$ yarn add @react-three/fiber
$ yarn add @react-three/drei
$ yarn add --dev leva
En cuanto al backend, vamos a estructurarlo de la siguiente manera:
├── audios/
├── bin
│ ├── CHANGELOG.md
│ ├── LICENSE.md
│ ├── README.adoc
│ ├── extras
│ │ ├── AdobeAfterEffects
│ │ ├── EsotericSoftwareSpine
│ │ └── MagixVegas
│ ├── include
│ │ ├── gmock
│ │ └── gtest
│ ├── lib
│ │ ├── cmake
│ │ ├── libgmock.a
│ │ ├── libgmock_main.a
│ │ ├── libgtest.a
│ │ ├── libgtest_main.a
│ │ └── pkgconfig
│ ├── res
│ │ └── sphinx
│ ├── rhubarb
│ └── tests
│ └── resources
├── index.js
├── modules
│ ├── defaultMessages.mjs
│ ├── elevenLabs.mjs
│ ├── lip-sync.mjs
│ ├── openAI.mjs
│ ├── rhubarbLipSync.mjs
│ └── whisper.mjs
├── package.json
├── tmp
├── utils
│ ├── audios.mjs
│ └── files.mjs
└── yarn.lock
E instalamos las siguientes dependencias:
yarn add elevenlabs-node
yarn add langchain
yarn add @langchain/openai
yarn add zod
En el frontend/src/App.js, implementaremos el siguiente código base:
// frontend/src/App.jsx
import { Loader } from '@react-three/drei'
import { Canvas } from '@react-three/fiber'
import { Leva } from 'leva'
import { Scenario } from './components/Scenario'
import { ChatInterface } from './components/ChatInterface'
function App() {
return (
<>
<Loader />
<Leva collapsed />
<ChatInterface />
<Canvas shadows camera={{ position: [0, 0, 0], fov: 10 }}>
<Scenario />
</Canvas>
</>
)
}
export default App
En el código anterior, hemos configurado los componentes principales de una aplicación React integrando gráficos 3D utilizando Three.js junto con la biblioteca @react-three/fiber. Comenzamos importando Loader de @react-three/drei para manejar la visualización de la carga de recursos 3D, asegurando una experiencia de usuario fluida durante el inicio de la aplicación.
Para representar la escena 3D, utilizamos el componente Canvas de @react-three/fiber, que sirve como contenedor para todos los elementos visuales 3D. En este caso, el Canvas tiene las sombras habilitadas (shadows), y la cámara está configurada con una posición inicial de [0, 0, 0] y un campo de visión (fov) de 10. La cámara se ha colocado en el centro de la escena, proporcionando una vista inicial neutral para el usuario.
Además, hemos integrado LEVA, una herramienta que proporciona un panel de control para manipular variables en tiempo real sin cambiar el código.
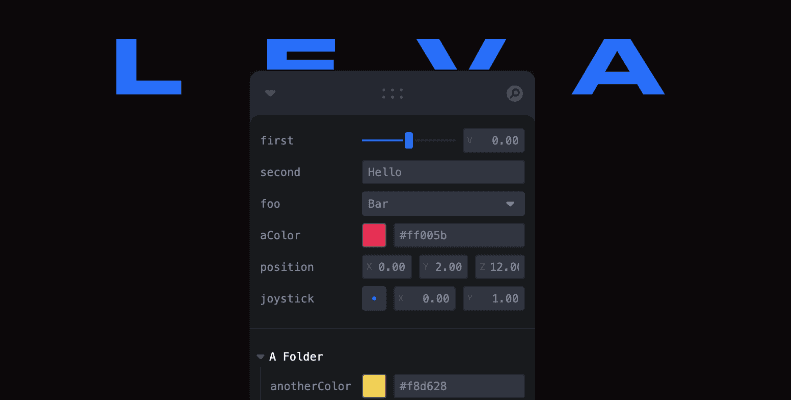
Figura 1. Panel de control LEVA.
El componente Scenario representa el núcleo de nuestra escena 3D, donde se colocan todos los objetos, luces y configuraciones específicas del entorno. Este componente se ve así:
// frontend/src/components/Scenario.jsx
import { CameraControls, Environment } from '@react-three/drei'
import { useEffect, useRef } from 'react'
export const Scenario = () => {
const cameraControls = useRef()
useEffect(() => {
cameraControls.current.setLookAt(0, 2.2, 5, 0, 1.0, 0, true)
}, [])
return (
<>
<CameraControls ref={cameraControls} />
<Environment preset="sunset" />
</>
)
}
En el componente Scenario, hemos utilizado algunos elementos proporcionados por la biblioteca @react-three/drei, un conjunto de abstracciones útiles para react-three-fiber. A continuación se muestran los elementos utilizados en el componente Scenario:
<CameraControls>: Este componente maneja los controles de la cámara, permitiendo a los usuarios interactuar con la vista 3D. Por ejemplo, el usuario podría orbitar alrededor de un objeto y acercar o alejar la vista.<Environment>: Este componente establece el entorno de la escena. Al usar el presetsunset, añade automáticamente iluminación y un fondo que simula una puesta de sol. El presetsunsetayuda a mejorar la apariencia visual de la escena sin necesidad de configurar manualmente las luces y el fondo.
El componente Scenario devuelve un fragmento JSX que contiene estos tres elementos. Cuando se renderiza, este componente configura los controles de la cámara, define el entorno y añade sombras de contacto a la escena 3D. También prepara la escena para que se añadan otros componentes 3D (como modelos, luces adicionales, etc.) y se presenten con una apariencia básica y controles ya establecidos.
El Avatar
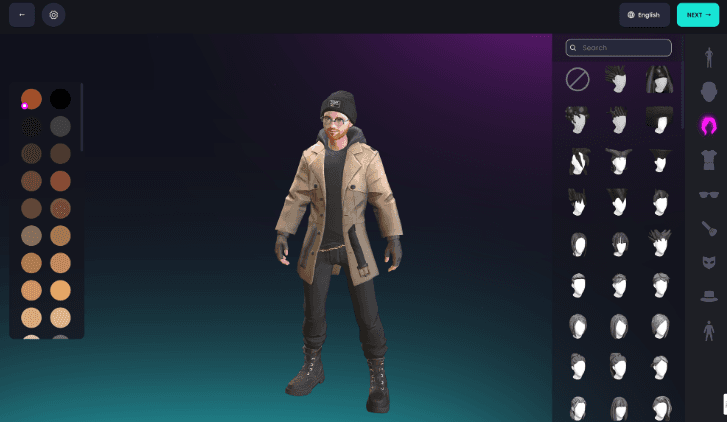
Figura 2. El editor de avatares de Ready Player Me.
El siguiente paso es obtener un avatar para integrarlo en nuestro componente Scenario. Para hacer esto, accederemos a la página Ready Player Me y crearemos nuestro avatar. No se requiere registro.
En este sitio, podemos personalizar nuestros avatares ajustando el género, el tono de piel, los accesorios, el estilo y color del cabello, la forma de la cara, la forma de los ojos y la ropa.
Una vez que tu avatar esté listo, copiamos el enlace del avatar y lo modificamos de la siguiente manera, añadiendo los parámetros de consulta morphTargets=ARKit, Oculus Visemes:
https://models.readyplayer.me/TU_ID_DE_AVATAR.glb?morphTargets=ARKit,Oculus Visemes
Al añadir los parámetros de consulta, podemos descargar el archivo .glb con los atributos para animar la boca, los ojos y la cara en general del avatar. Aquí, puedes consultar el resto de los parámetros de consulta que podemos usar. Una vez que nuestro avatar esté descargado, lo colocamos en el directorio public/model con un nombre de tu elección. En mi caso, lo he llamado avatar.glb.
Con el archivo avatar.glb, vamos a gltf.pmnd.rs para crear nuestro componente React para nuestro avatar. Si decides usar TypeScript, es necesario especificar que también necesitas los tipos correspondientes.

Figura 3. Editor GLTF para generar componentes React.js.
Dado que no estamos usando TypeScript en nuestro caso, el código generado para nuestro avatar sería el siguiente:
// frontend/src/components/Avatar.jsx
import React, { useRef } from 'react'
import { useGLTF } from '@react-three/drei'
export function Avatar(props) {
const { nodes, materials } = useGLTF('/models/avatar.glb')
return (
<group {...props} dispose={null}>
<primitive object={nodes.Hips} />
<skinnedMesh
name="EyeLeft"
geometry={nodes.EyeLeft.geometry}
material={materials.Wolf3D_Eye}
skeleton={nodes.EyeLeft.skeleton}
morphTargetDictionary={nodes.EyeLeft.morphTargetDictionary}
morphTargetInfluences={nodes.EyeLeft.morphTargetInfluences}
/>
<skinnedMesh
name="EyeRight"
geometry={nodes.EyeRight.geometry}
material={materials.Wolf3D_Eye}
skeleton={nodes.EyeRight.skeleton}
morphTargetDictionary={nodes.EyeRight.morphTargetDictionary}
morphTargetInfluences={nodes.EyeRight.morphTargetInfluences}
/>
<skinnedMesh
name="Wolf3D_Head"
geometry={nodes.Wolf3D_Head.geometry}
material={materials.Wolf3D_Skin}
skeleton={nodes.Wolf3D_Head.skeleton}
morphTargetDictionary={nodes.Wolf3D_Head.morphTargetDictionary}
morphTargetInfluences={nodes.Wolf3D_Head.morphTargetInfluences}
/>
<skinnedMesh
name="Wolf3D_Teeth"
geometry={nodes.Wolf3D_Teeth.geometry}
material={materials.Wolf3D_Teeth}
skeleton={nodes.Wolf3D_Teeth.skeleton}
morphTargetDictionary={nodes.Wolf3D_Teeth.morphTargetDictionary}
morphTargetInfluences={nodes.Wolf3D_Teeth.morphTargetInfluences}
/>
<skinnedMesh
geometry={nodes.Wolf3D_Glasses.geometry}
material={materials.Wolf3D_Glasses}
skeleton={nodes.Wolf3D_Glasses.skeleton}
/>
<skinnedMesh
geometry={nodes.Wolf3D_Headwear.geometry}
material={materials.Wolf3D_Headwear}
skeleton={nodes.Wolf3D_Headwear.skeleton}
/>
<skinnedMesh
geometry={nodes.Wolf3D_Body.geometry}
material={materials.Wolf3D_Body}
skeleton={nodes.Wolf3D_Body.skeleton}
/>
<skinnedMesh
geometry={nodes.Wolf3D_Outfit_Bottom.geometry}
material={materials.Wolf3D_Outfit_Bottom}
skeleton={nodes.Wolf3D_Outfit_Bottom.skeleton}
/>
<skinnedMesh
geometry={nodes.Wolf3D_Outfit_Footwear.geometry}
material={materials.Wolf3D_Outfit_Footwear}
skeleton={nodes.Wolf3D_Outfit_Footwear.skeleton}
/>
<skinnedMesh
geometry={nodes.Wolf3D_Outfit_Top.geometry}
material={materials.Wolf3D_Outfit_Top}
skeleton={nodes.Wolf3D_Outfit_Top.skeleton}
/>
</group>
)
}
useGLTF.preload('/models/avatar.glb')
El código anterior contiene un componente React llamado Avatar, que carga y renderiza el modelo 3D avatar.glb usando Three.js a través de la biblioteca @react-three/drei. Este componente utiliza el hook useGLTF para cargar un archivo GLB, un formato binario de glTF (GL Transmission Format), una especificación estándar para la distribución eficiente de modelos 3D.
Componente avatar 3D y animaciones
El componente anterior realiza lo siguiente:
Carga del modelo 3D: El hook
useGLTFcarga el modelo 3D desde la ruta proporcionada (models/avatar.glb). Una vez cargado, este hook devuelve dos objetos importantes:nodes, que contiene todos los nodos o elementos del modelo, ymaterials, que almacena los materiales definidos en el modelo 3D.Estructura del componente: El componente Avatar devuelve un elemento
<group>deThree.js, que actúa como contenedor para todos los elementos hijos. Este grupo recibe cualquierpropadicional pasado al componente Avatar a través de{...props}y evita que el recolector de basura de JavaScript elimine el grupo cuando no está en uso estableciendodispose={null}.Mallas con skinning: Dentro del grupo, se crean múltiples componentes
<skinnedMesh>, cada uno representando una parte del avatar con su propia geometría, material y esqueleto. Las mallas con skinning permiten animaciones complejas, como expresiones faciales o movimiento de personajes, ya que sus vértices están vinculados a un sistema de huesos (esqueleto).Morph Targets: Algunas mallas incluyen
morphTargetDictionaryymorphTargetInfluences, que se utilizan para animaciones basadas en morph targets. Estas animaciones deforman la malla de manera controlada para crear expresiones faciales o movimientos sutiles.Precarga: Finalmente, se utiliza
useGLTF.preload("models/avatar.glb")para precargar el modelo 3D en segundo plano lo antes posible, lo que puede mejorar la experiencia del usuario al reducir el tiempo de espera cuando el componente Avatar se monta por primera vez.
El código anterior define un componente Avatar que renderiza un avatar 3D interactivo con partes móviles y expresiones faciales. Este avatar está listo para ser integrado en una escena 3D más grande o utilizado como un elemento independiente dentro de una aplicación web.
Ahora, actualizaremos nuestro componente Scenario de la siguiente manera:
// frontend/src/components/Scenario.jsx
import { CameraControls, Environment } from '@react-three/drei'
import { useEffect, useRef } from 'react'
import { Avatar } from './Avatar'
export const Scenario = () => {
const cameraControls = useRef()
useEffect(() => {
cameraControls.current.setLookAt(0, 2.2, 5, 0, 1.0, 0, true)
}, [])
return (
<>
<CameraControls ref={cameraControls} />
<Environment preset="sunset" />
<Avatar />
</>
)
}
Y colocamos nuestro avatar lejos de la cámara:
//frontend/src/components/Avatar.js
// Código omitido por simplicidad
<group {...props} dispose={null} position={[0, -0.65, 0]}>
// Código omitido por simplicidad
El resultado debería verse algo así:

Figura 4. Vista previa del avatar renderizado.
Animaciones
Como mencionamos anteriormente, una de las características fundamentales de los avatares de IA son sus movimientos corporales. Para cumplir con este requisito, realizaremos dos tareas en esta sección:
- Usar Mixamo para animar todo el cuerpo y agregar movimientos como bailar, saludar, correr, etc.
- Agregar un parpadeo natural a los ojos para hacerlos más realistas.
Movimientos corporales con animaciones de Mixamo
Para usar Mixamo, primero debemos convertir nuestro modelo avatar.glb en un formato de archivo .fbx. Para hacer esto, usaremos Blender, siguiendo estos pasos:
- Instalar Blender en nuestro ordenador.
- Crear un nuevo proyecto de tipo general:
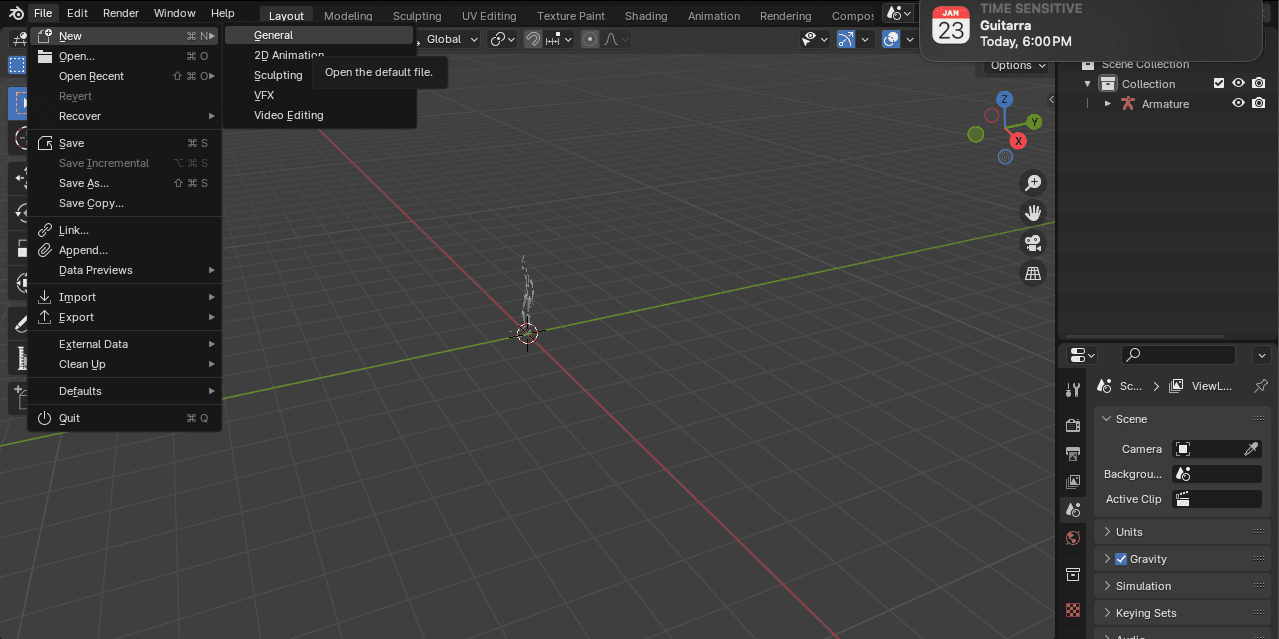
Figura 5. Iniciar un nuevo proyecto de tipo General.
- Eliminar todos los elementos de la escena e importar el archivo
avatar.glb:
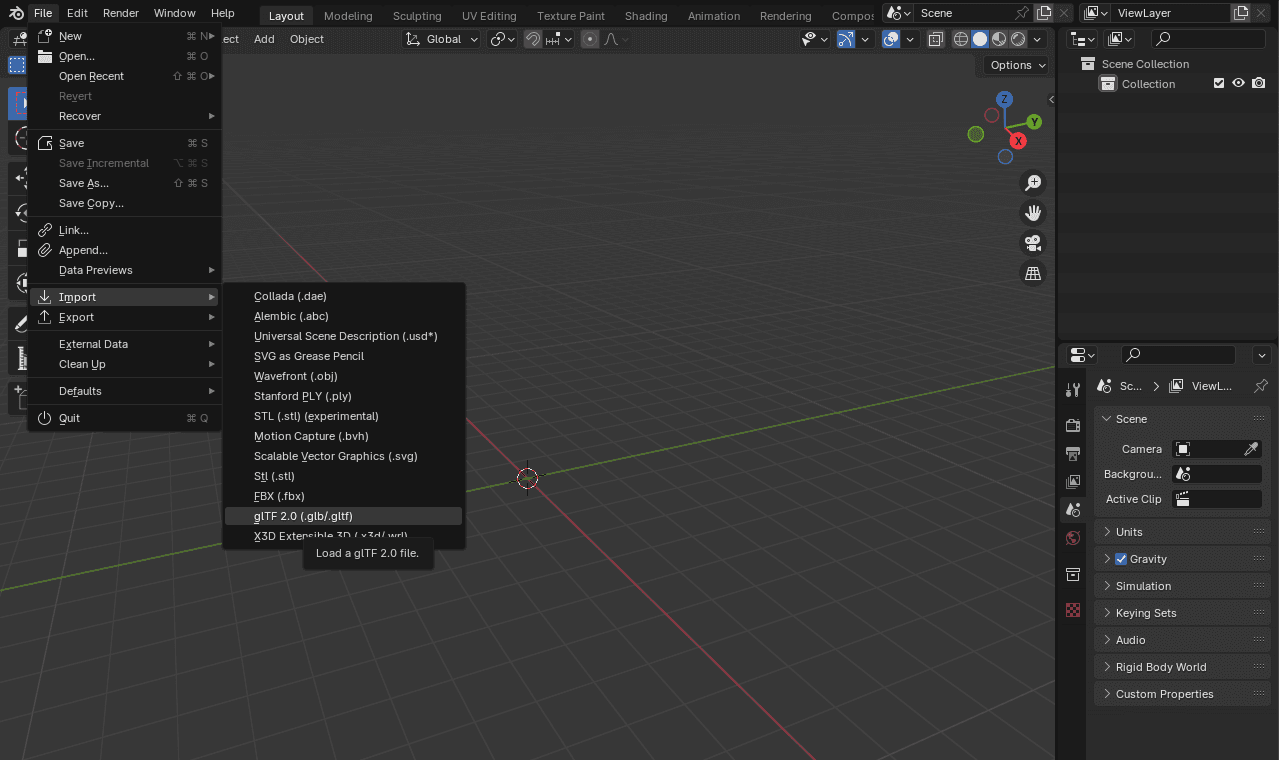
Figura 6. Importar un archivo .glb/.gltf.
Al seleccionar nuestro archivo, ajustamos el parámetro Bone Dir en Temperance, como se muestra en la imagen:
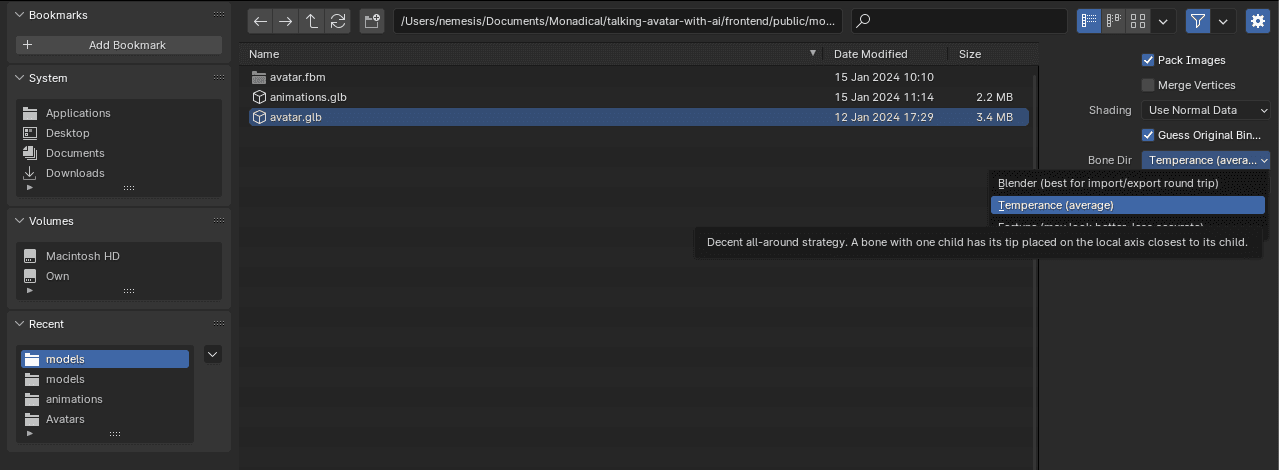
Figura 7. Establecer el parámetro Bone Dir en Temperance.
Si se hace correctamente, nuestro avatar debería verse así en Blender:
Figura 8. Modelo GLFT en Blender.
- Exportar el archivo en formato
.fbx.
Figura 9. Exportar en formato FBX.
Debemos asegurarnos de que el parámetro Path Mode esté establecido en copy:
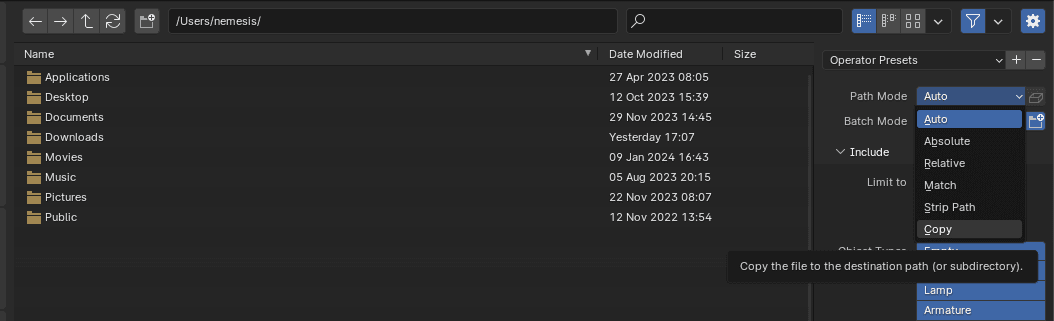
Figura 10. Establecer el parámetro Path Mode en copy.
Y finalmente, los exportamos a nuestro directorio frontend/public/models.
Ahora que tenemos nuestro modelo en formato FBX, vamos a https://www.mixamo.com/, nos registramos y subimos el archivo avatar.fbx. Aquí encontraremos una variedad de animaciones en las que podemos animar nuestro avatar. Recuerda, la idea aquí es hacer que nuestro avatar actúe de la manera más realista posible.
Como se muestra en el GIF, he enseñado a mi avatar digital a bailar hip-hop:
Figura 11. Felix, el humano digital de este post, está mostrando sus mejores movimientos de hip-hop.
Antes de continuar, quiero explicar la relación entre estas animaciones con OpenAI GPT o cualquier otro modelo de lenguaje que deseemos implementar. En el backend, vamos a implementar un módulo de integración de OpenAI GPT para estas animaciones. Este módulo manejará la sincronización entre las respuestas generadas y las animaciones correspondientes, asegurando que los movimientos y expresiones faciales del avatar coincidan con el contexto y el flujo de la conversación.
Al hacer esto, mejoramos la experiencia general del usuario, haciendo que las interacciones se sientan más naturales. El código para este módulo se ve así:
// backend/modules/openAI.mjs
import { ChatOpenAI } from '@langchain/openai'
import { ChatPromptTemplate } from '@langchain/core/prompts'
import { StructuredOutputParser } from 'langchain/output_parsers'
import { z } from 'zod'
import dotenv from 'dotenv'
dotenv.config()
const template = `
You are Felix, a world traveler.
You will always respond with a JSON array of messages, with a maximum of 3 messages:
\n{format_instructions}.
Each message has properties for text, facialExpression, and animation.
The different facial expressions are: smile, sad, angry, surprised, funnyFace, and default.
The different animations are: Idle, TalkingOne, TalkingThree, SadIdle, Defeated, Angry,
Surprised, DismissingGesture and ThoughtfulHeadShake.
`
const prompt = ChatPromptTemplate.fromMessages([
['ai', template],
['human', '{question}'],
])
const model = new ChatOpenAI({
openAIApiKey: process.env.OPENAI_API_KEY || '-',
modelName: process.env.OPENAI_MODEL || 'davinci',
temperature: 0.2,
})
const parser = StructuredOutputParser.fromZodSchema(
z.object({
messages: z.array(
z.object({
text: z.string().describe('Text to be spoken by the AI'),
facialExpression: z
.string()
.describe(
'Facial expression to be used by the AI. Select from: smile, sad, angry, surprised, funnyFace, and default'
),
animation: z.string().describe(
`Animation to be used by the AI. Select from: Idle, TalkingOne, TalkingThree, SadIdle,
Defeated, Angry, Surprised, DismissingGesture, and ThoughtfulHeadShake.`
),
})
),
})
)
const openAIChain = prompt.pipe(model).pipe(parser)
export { openAIChain, parser }
En este código, usamos @langchain/openai para crear un sistema de chat interactivo que incorpora respuestas animadas y expresiones faciales utilizando la inteligencia artificial de OpenAI. En la variable template, instruimos a la IA para que actúe como un personaje llamado Felix, un viajero del mundo. También especificamos que Felix siempre debe responder con un array JSON que contiene mensajes. Las respuestas deben seguir un formato específico en el que cada elemento tiene propiedades definidas para el texto que dirá Felix, su expresión facial y la animación o movimiento que realizará.
Las expresiones faciales que Felix puede usar al responder son una sonrisa, tristeza (sad), enojo (angry), sorpresa (surprised), cara graciosa (funnyFace) y una expresión predeterminada (default). Estas expresiones humanizan las respuestas generadas por la IA. Además, detallamos algunas animaciones que Felix puede ejecutar mientras responde, como Idle, TalkingOne, TalkingThree, SadIdle, Defeated, Angry, Surprised, DismissingGesture y ThoughtfulHeadShake. Estas animaciones hacen que la interacción sea más dinámica y entretenida, proporcionando un elemento adicional que acompaña al texto generado:
const parser = StructuredOutputParser.fromZodSchema(
z.object({
messages: z.array(
z.object({
text: z.string().describe('Text to be spoken by the AI'),
facialExpression: z
.string()
.describe(
'Facial expression to be used by the AI. Select from: smile, sad, angry, surprised, funnyFace, and default'
),
animation: z.string().describe(
`Animation to be used by the AI. Select from: Idle, TalkingOne, TalkingThree, SadIdle,
Defeated, Angry, Surprised, DismissingGesture, and ThoughtfulHeadShake.`
),
})
),
})
)
Utilizamos la biblioteca zod para implementar un esquema que valida la estructura de la respuesta para asegurar que la respuesta siempre tenga el array JSON deseado. Este esquema actúa como una plantilla que define la estructura y el contenido de la respuesta.
Si quieres aprender más sobre cómo hacer que los LLMs respondan a tus preguntas con una estructura de datos particular, te recomiendo que leas el artículo: How to Make LLMs Speak Your Language.
Hasta este punto, es importante notar que Felix responderá a un usuario no solo enviando texto generado, sino con una expresión facial apropiada para la situación que se está discutiendo. Para asegurar que estos elementos se adhieran a un estándar predefinido, hemos utilizado un esquema zod. Este esquema actúa como una plantilla que define cómo debe ser la respuesta en términos de su estructura y contenido.
Cada vez que Felix genera una respuesta, pasa por un proceso de validación con zod. zod inspecciona la respuesta y verifica que cada parte cumpla con las reglas establecidas en el esquema. Si todo está en orden, la respuesta se envía a Azure Cognitive Speech Service. Pero si algo no coincide, zod identifica el problema, permitiendo que se corrija antes de proceder. De esta manera, se evitan confusiones o malentendidos por una respuesta mal formada.
Ahora que entendemos el razonamiento detrás de las animaciones de Mixamo, exploremos formas de incorporarlas a nuestro modelo.
Primero seleccionaremos un conjunto de animaciones coherentes con la personalidad que queremos darle a nuestro avatar. En mi caso, he elegido diez de ellas:
Defeated: Mostrando frustración después de una pérdida
Angry: De pie enojado
Idle: Detenido, sin hacer nada
Idle: Inactivo feliz
Surprised: Encontrando algo y moviendo los dedos
Thoughtful headshake: Sacudiendo la cabeza pensativamente
Dismissing gesture: Descartando con el dorso de la mano
Talking One: Hablando con dos manos
Talking Two: Hablando con una mano
Sad idle: De pie en una disposición triste
Cuando hayas elegido tus animaciones, debemos descargar cada una de ellas sin piel, como podemos ver en la siguiente imagen:
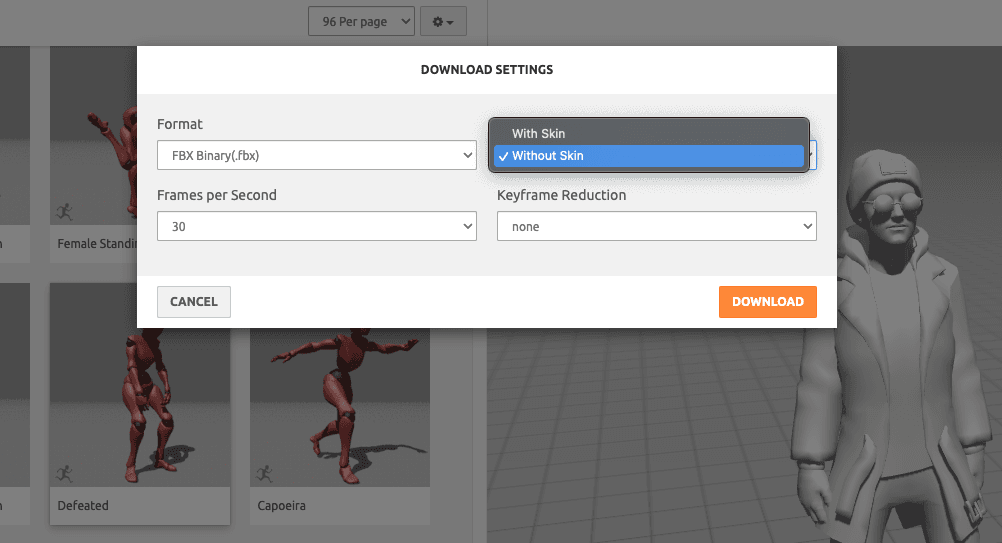
Figura 12. Descargar animaciones sin piel.
De esta manera, nos aseguramos de que solo descargamos los datos de la animación y los ubicamos en una carpeta a la que podamos acceder fácilmente. En mi caso, decidí colocarlos en el directorio frontend/public animations del proyecto.
A continuación, en Blender, creamos un nuevo proyecto de tipo general, eliminamos todos los elementos predeterminados e importamos una de las animaciones como archivo FBX:
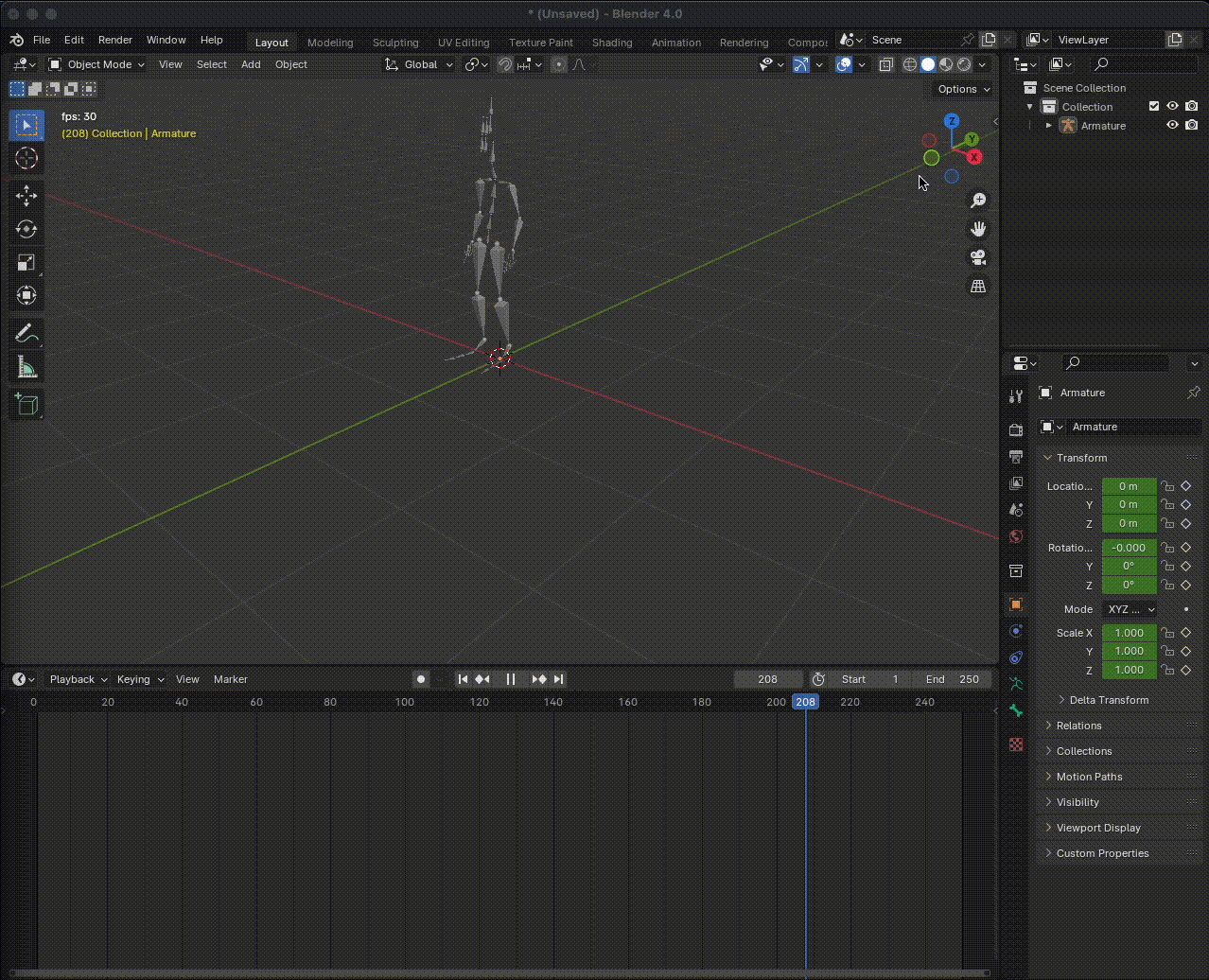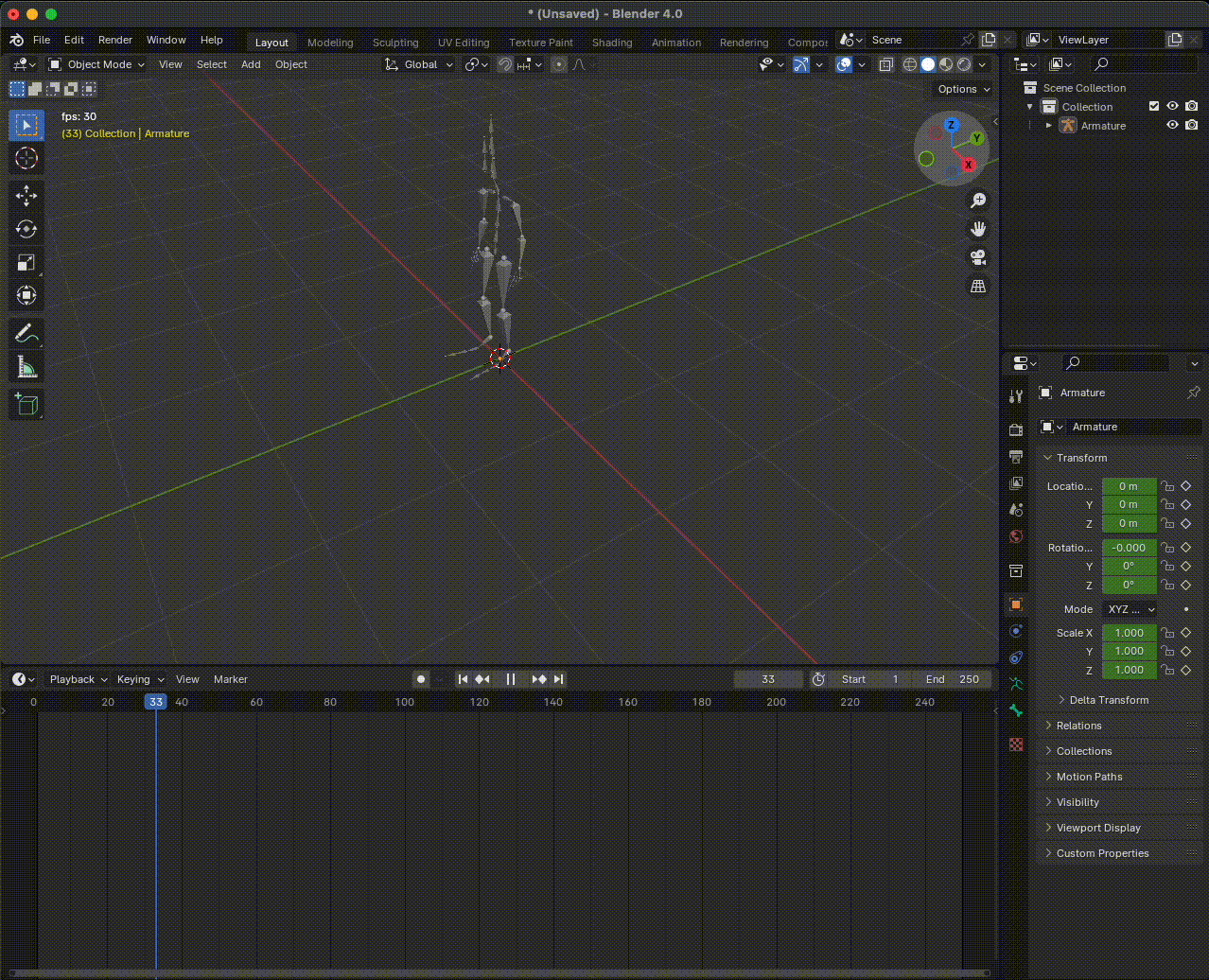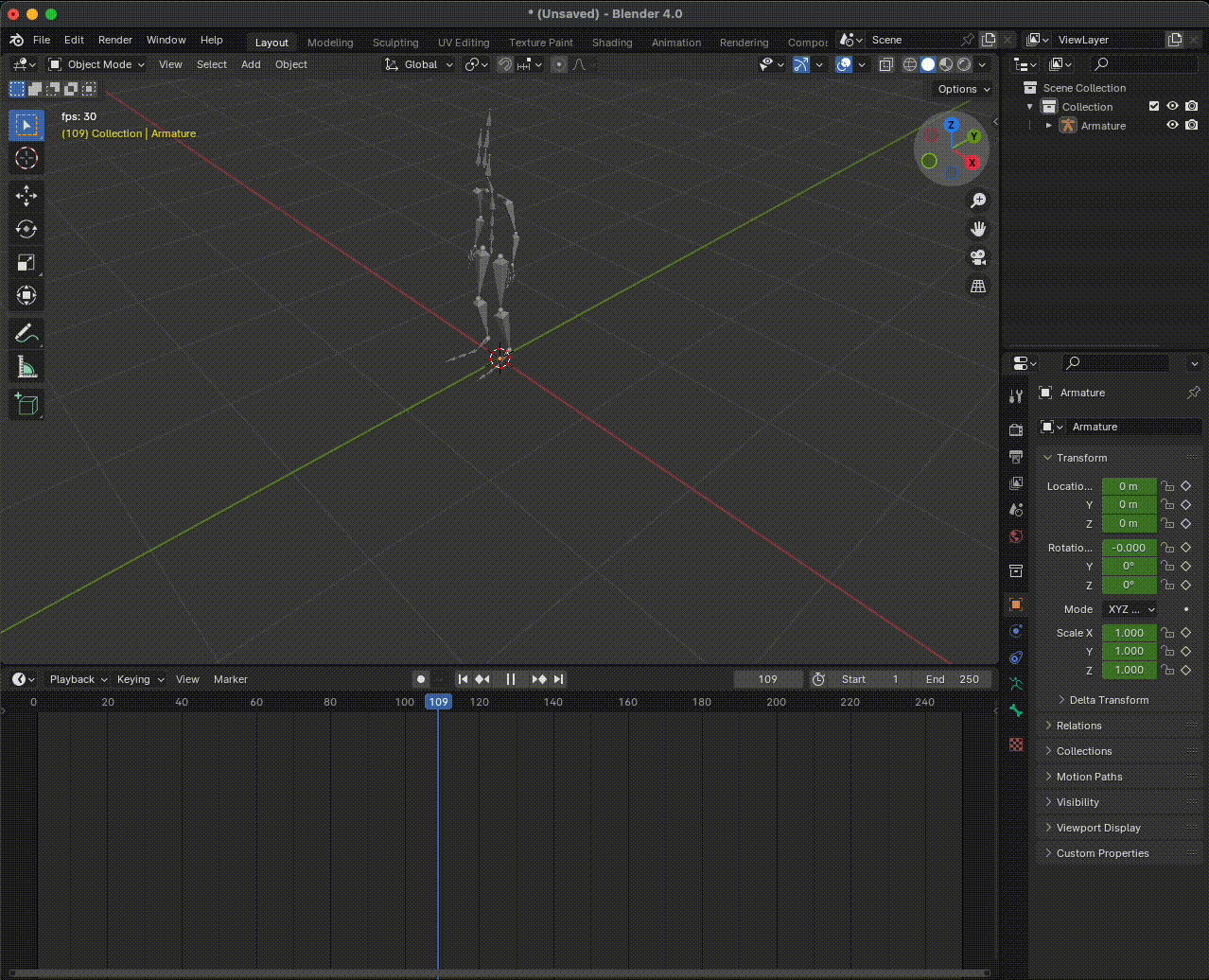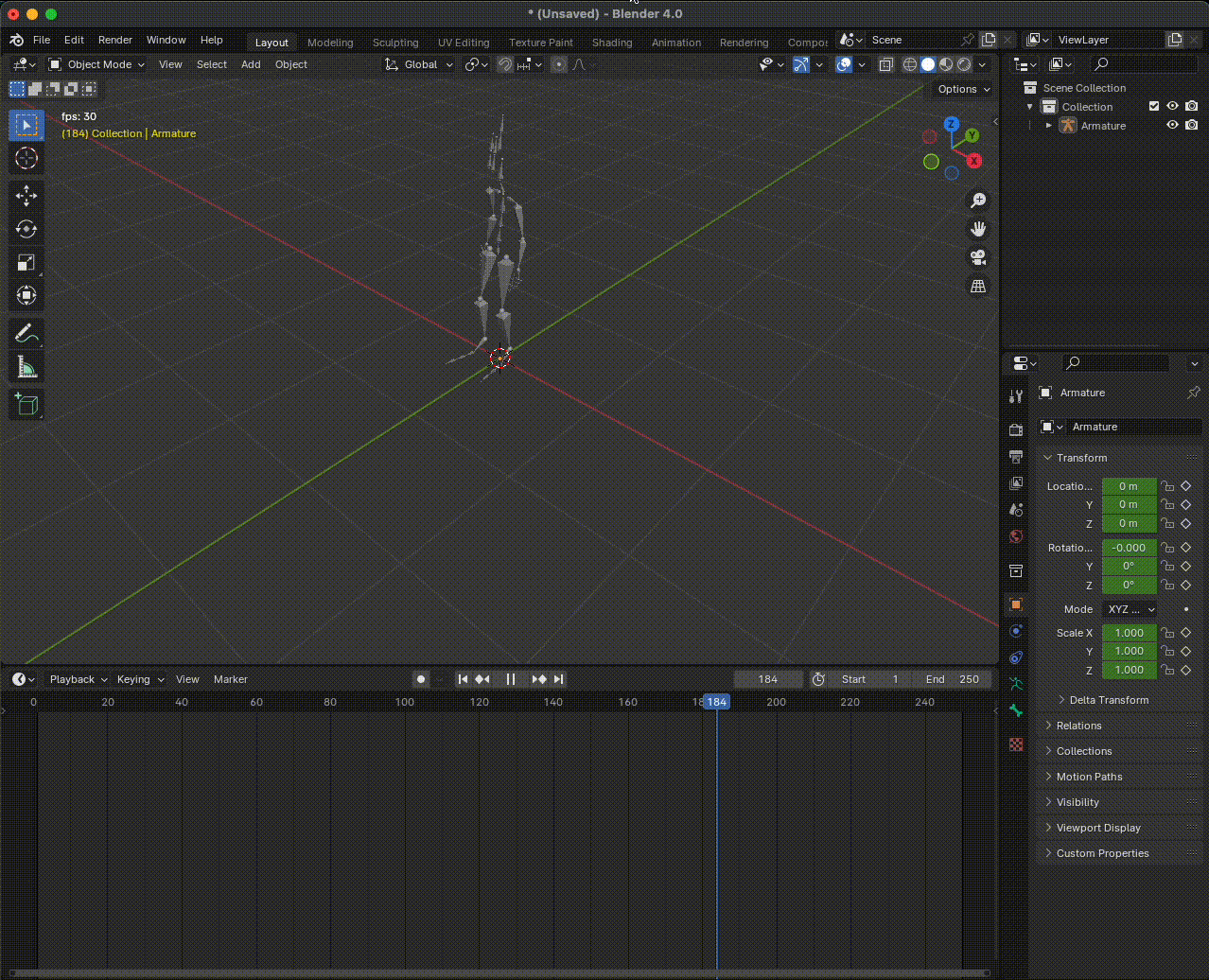
Figura 13. Vista previa de una animación de Mixamo. Debes presionar la tecla de espacio en tu teclado para ejecutarla o detenerla.
Si la hemos importado bien, nuestra animación debería verse como un esqueleto de huesos triangulares. Para ver cómo funciona la animación, presiona la tecla para reproducir o detener la animación.
Luego, en la sección Nonlinear Animation, podemos editar el nombre de la animación, que por defecto aparece similar a algo como Armature|mixamo.com|Layer0. La idea es usar nombres relacionados con emociones o sentimientos asociados con la animación para que cuando integremos el LLM, pueda construir mensajes y usar estas emociones para expresar sus sentimientos.
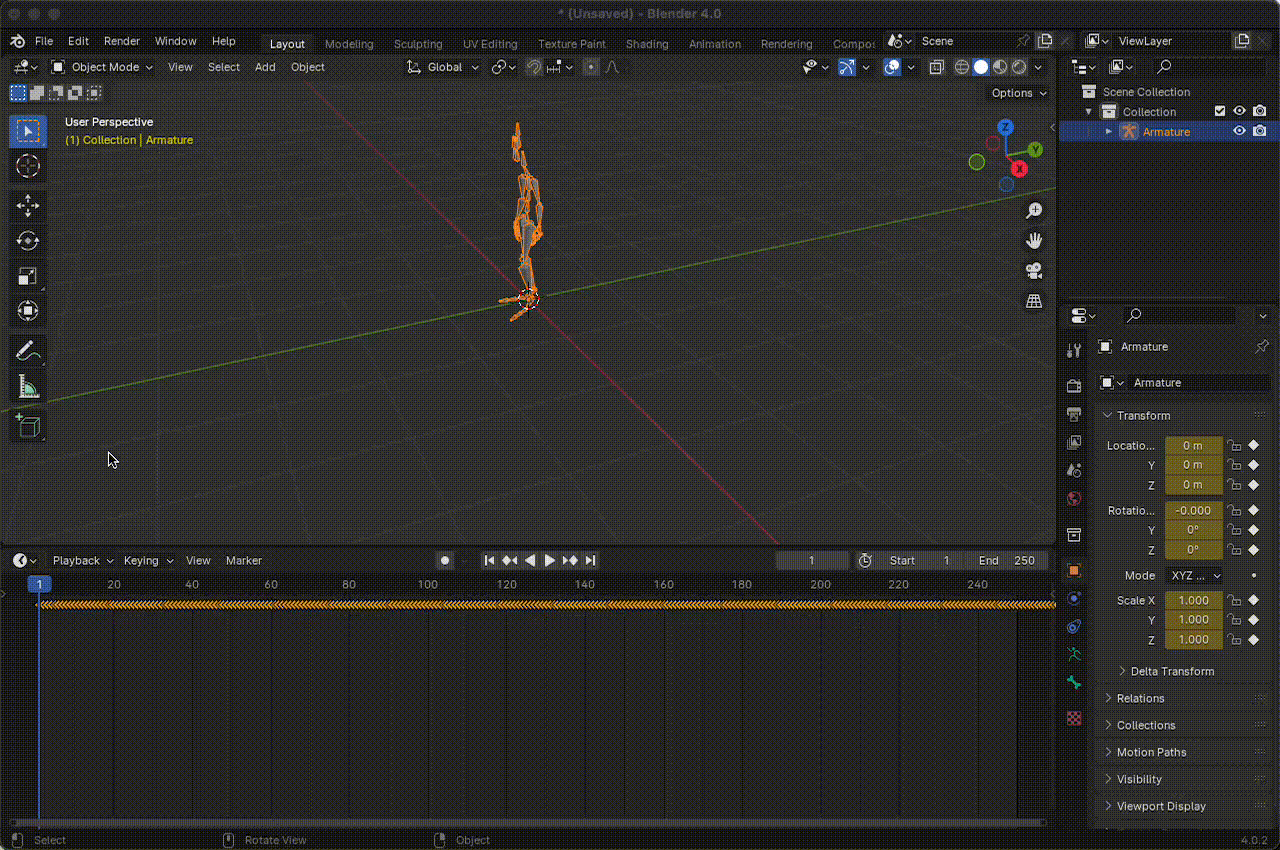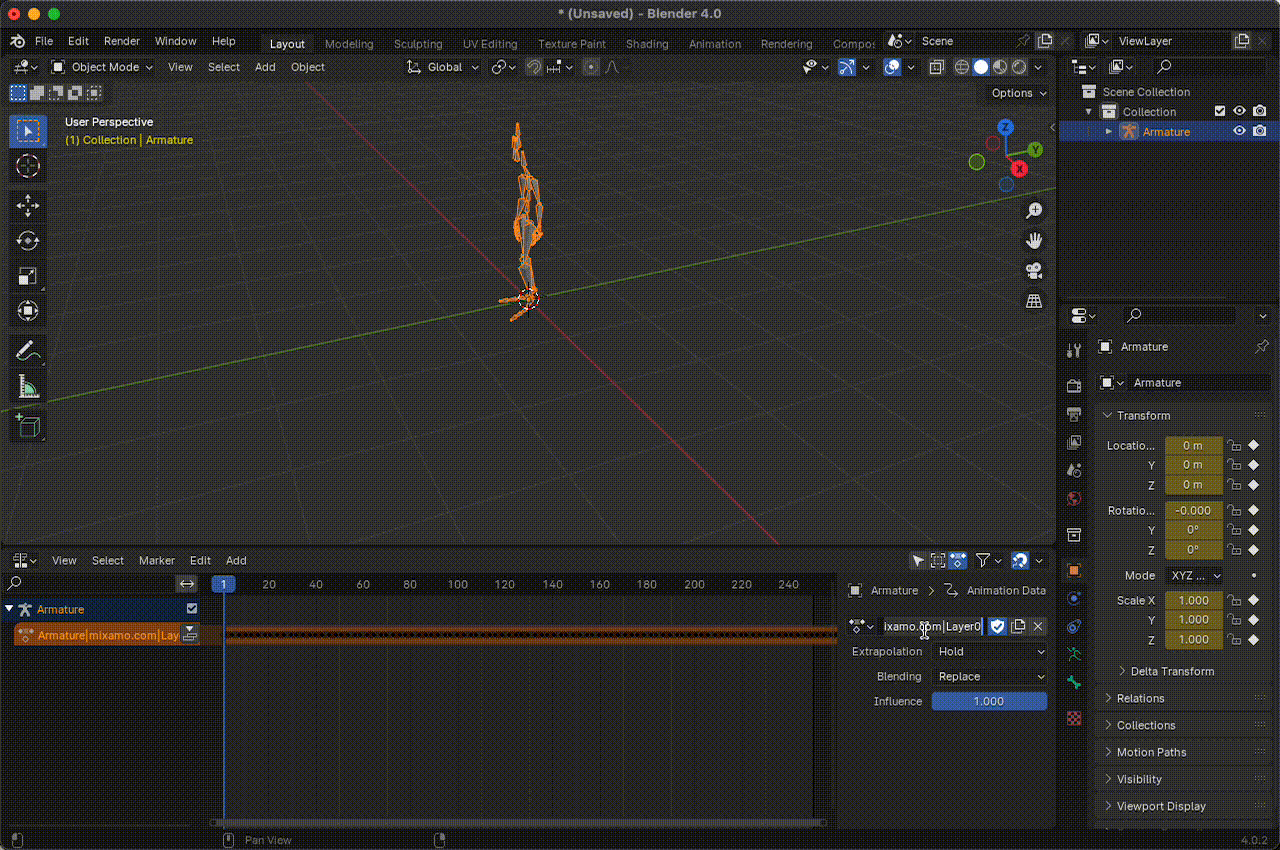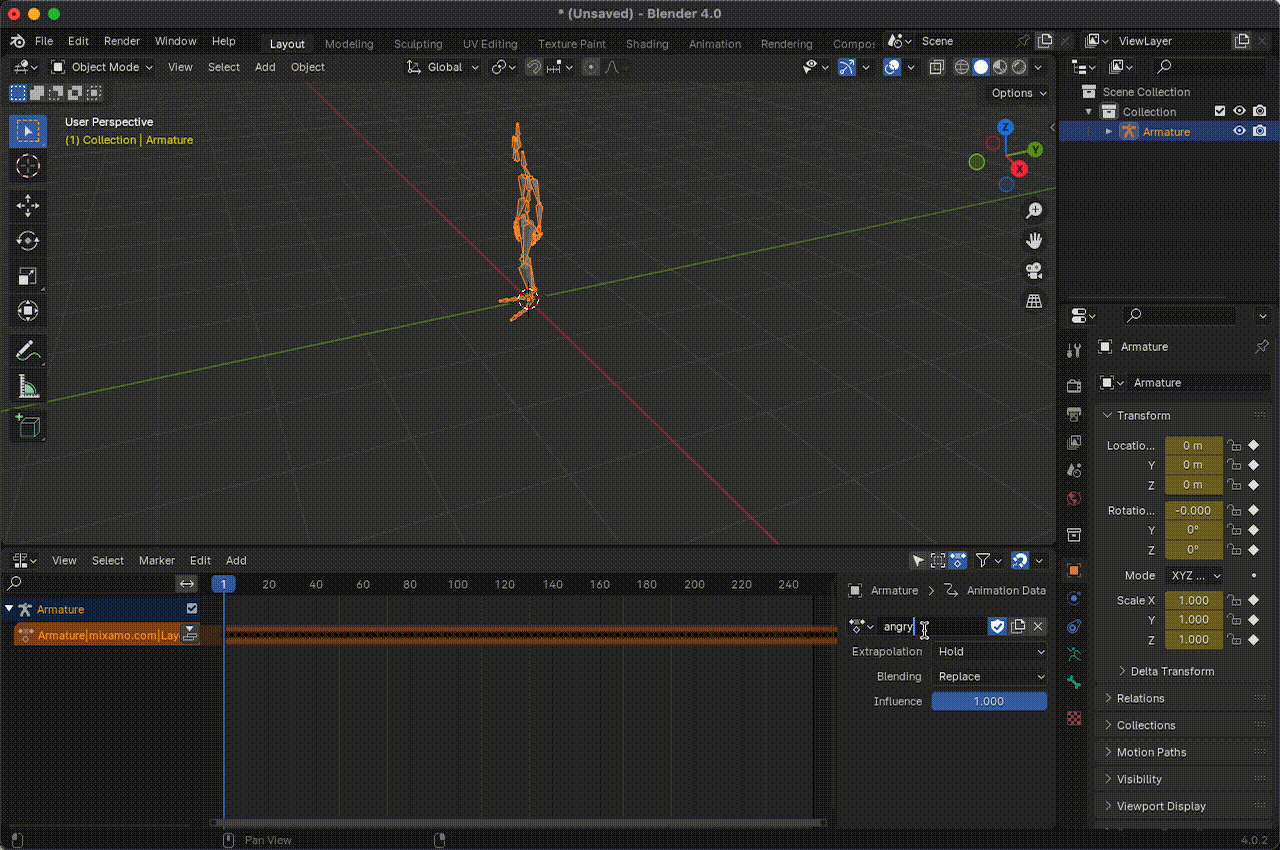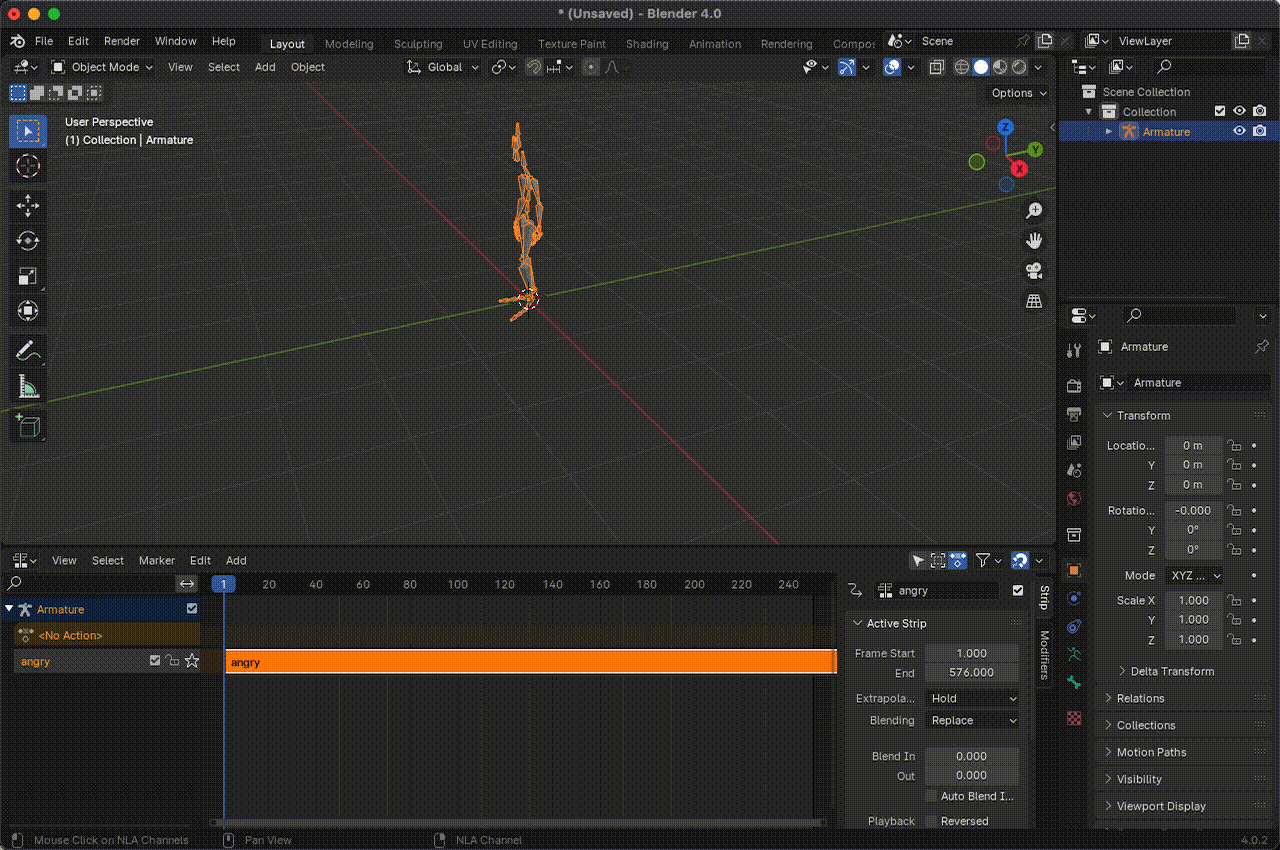
Figura 14. Cambiar el nombre de las animaciones.
El siguiente paso será añadir las otras animaciones de la siguiente manera:
Importar la animación como un archivo FBX.
Desarticular el
armatureeliminando la jerarquía de animación.
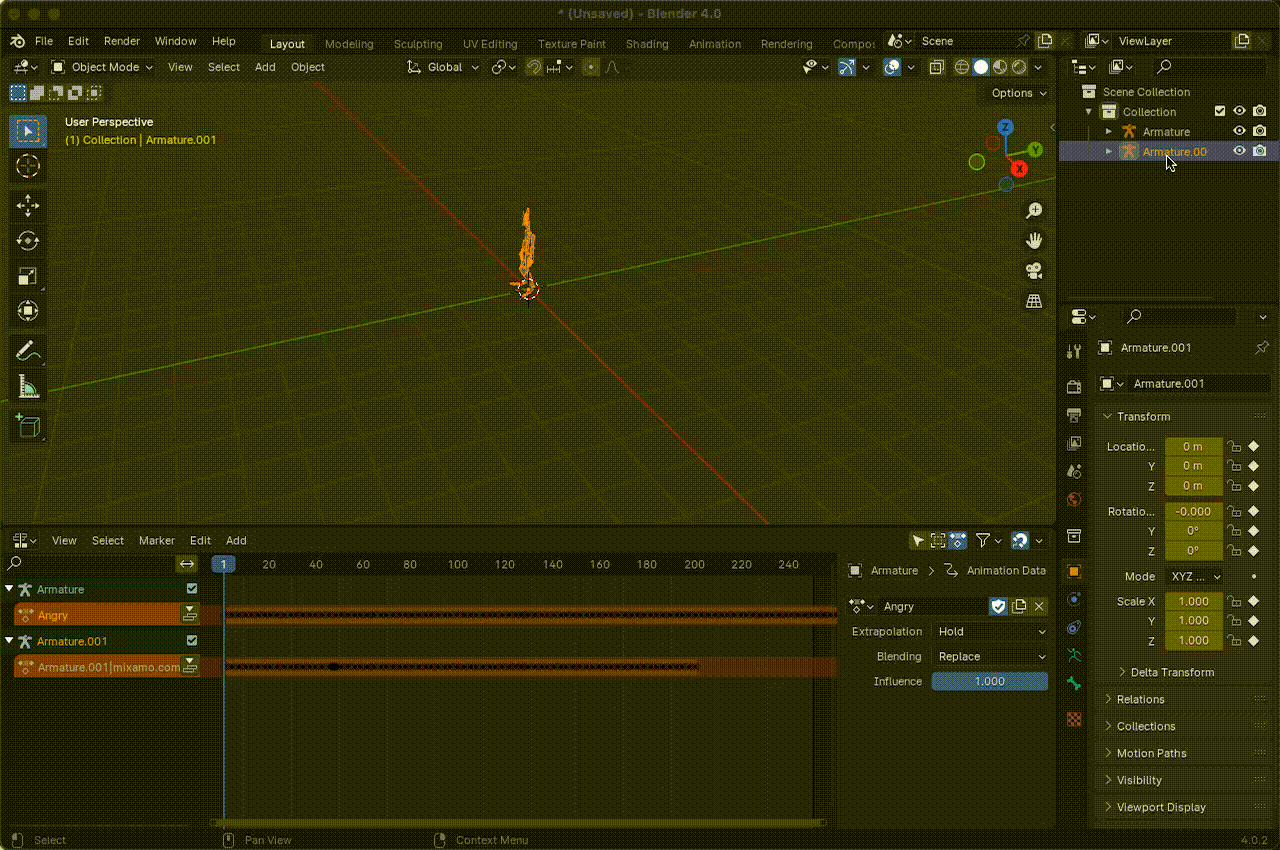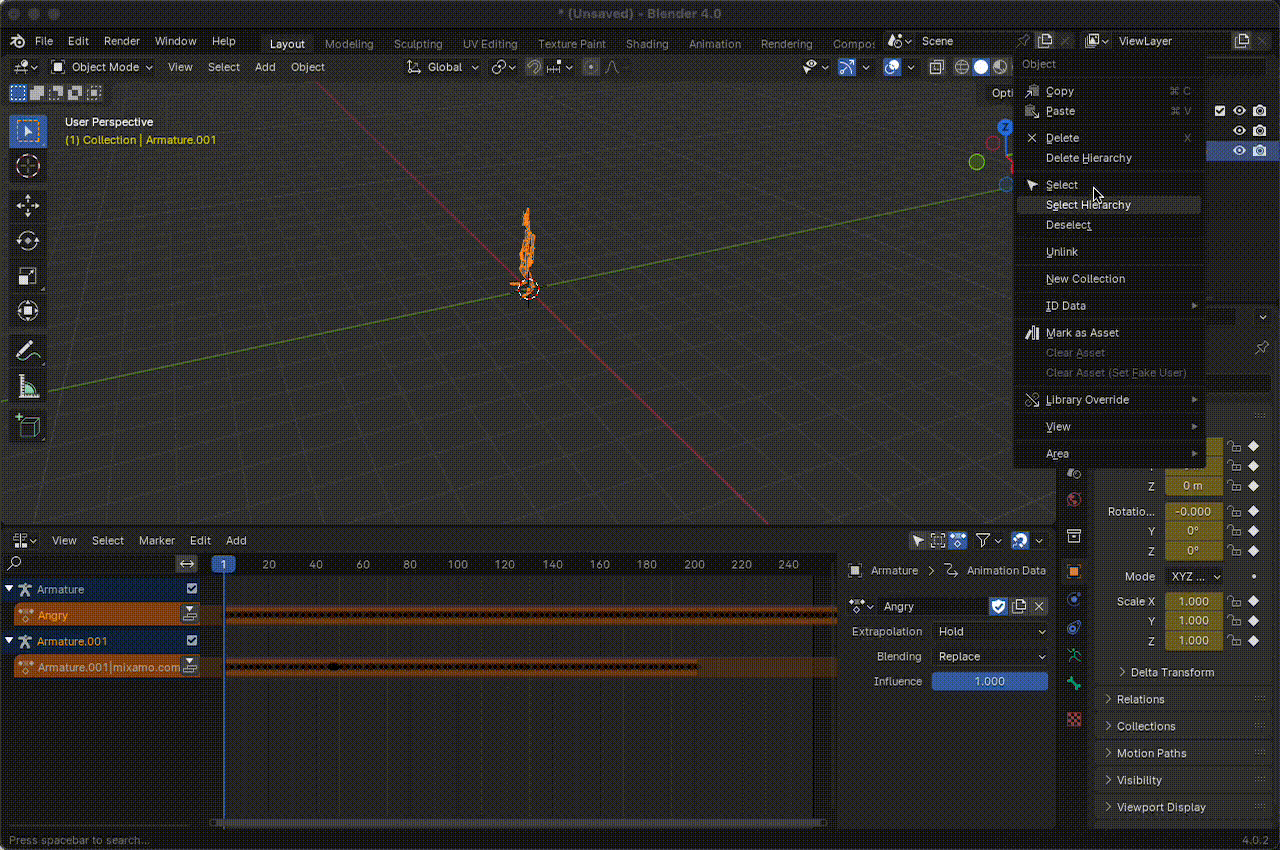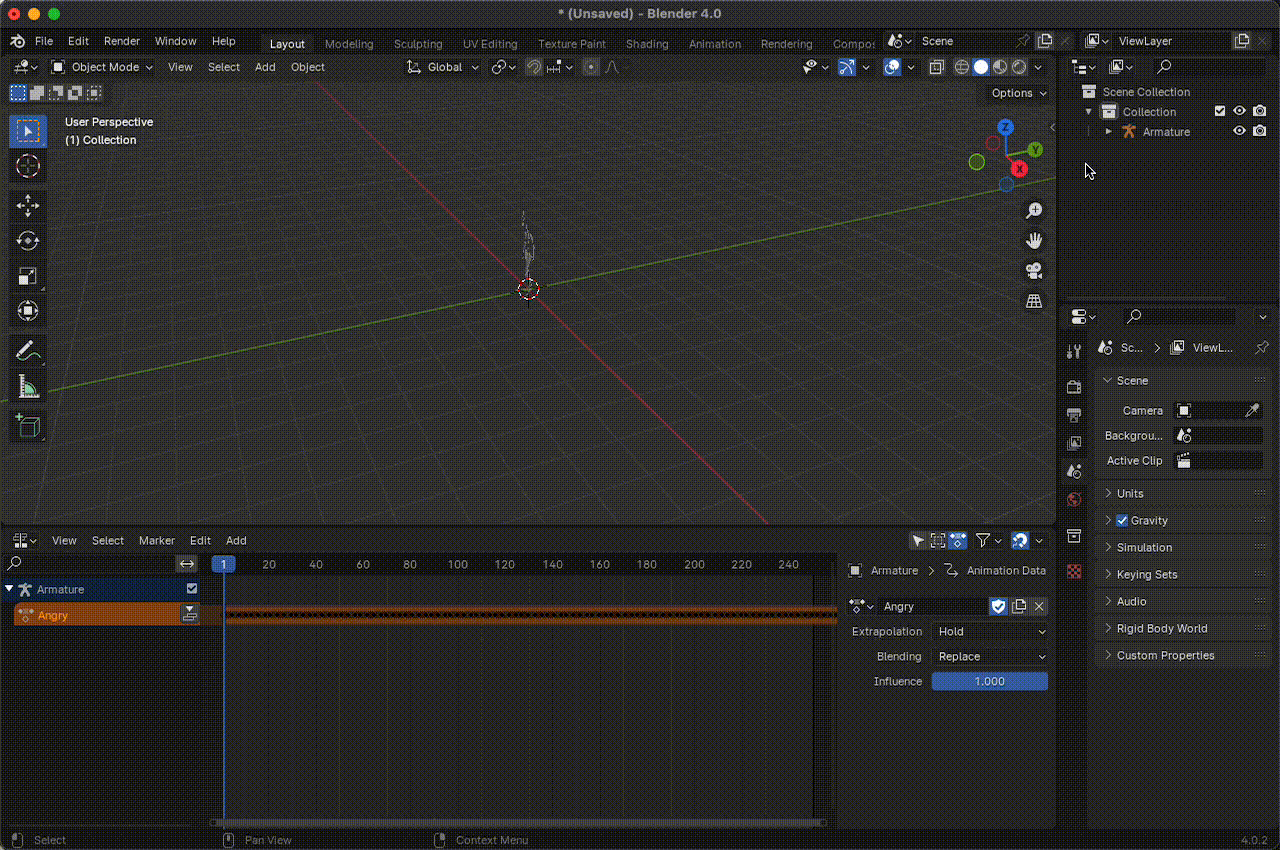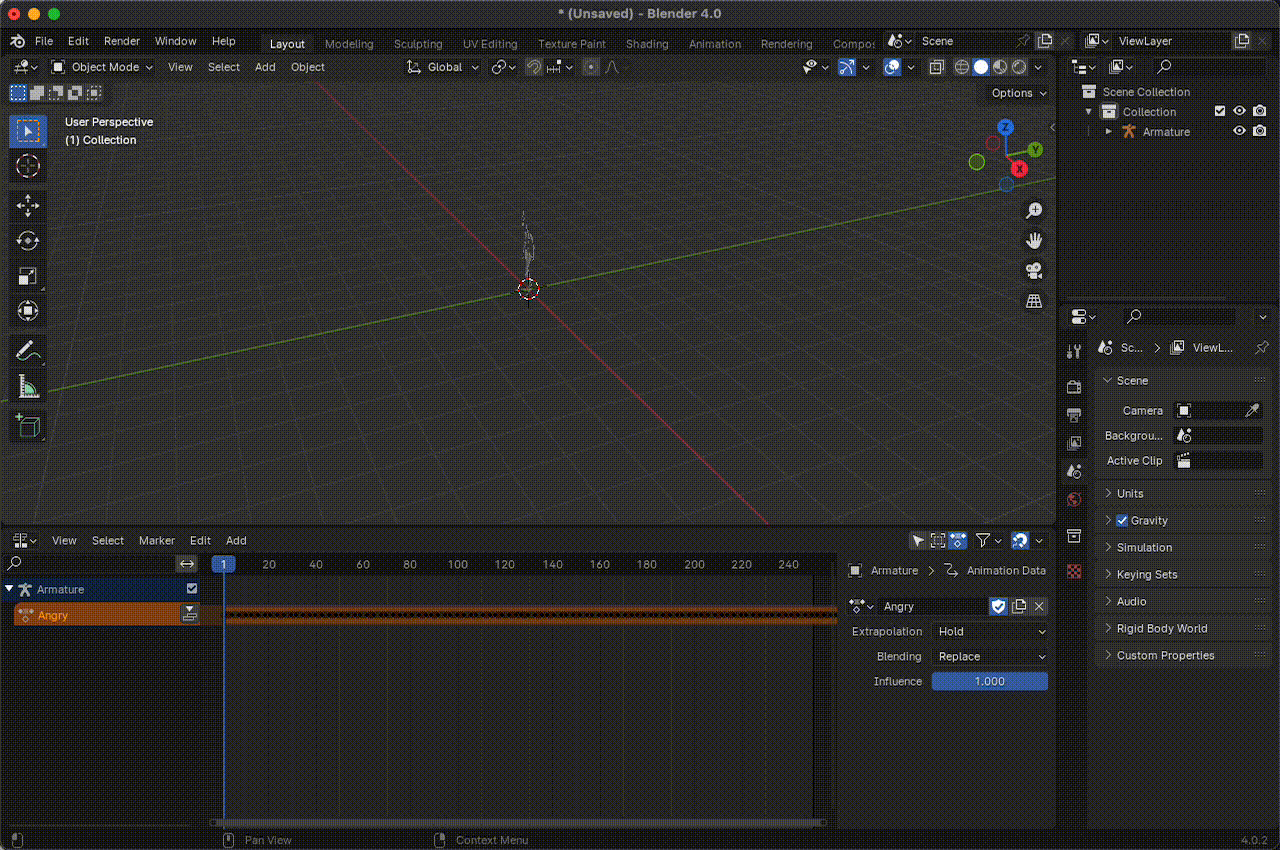
Figura 15. Desarticular el armature.
- Añadir una nueva acción y renombrar la animación. Utiliza nombres en formato
CamelCaseosnake_case.
Figura 16. Desarticular el armature.
- Repite los pasos anteriores con cada animación que quieras añadir a tu avatar.
Figura 16. Exportar el paquete de animaciones en formato glTF 2.0.
Una vez que nuestro paquete de animaciones esté listo, debemos exportarlo como un archivo .glb y colocarlo en el directorio public/models/. Para implementarlas en nuestro código, es suficiente hacer lo siguiente en el componente Avatar.js:
// frontend/src/components/Avatar.jsx
import { useAnimations, useGLTF } from "@react-three/drei";
const { animations } = useGLTF("/models/animations.glb");
const group = useRef();
const { actions, mixer } = useAnimations(animations, group);
const \[animation, setAnimation\] = useState(
animations.find((a) =\> a.name === "Idle") ? "Idle" :
animations\[0\].name);
useEffect(() =\> {
actions\[animation\]
.reset()
.fadeIn(mixer.stats.actions.inUse === 0 ? 0 : 0.5)
.play();
return () =\> actions\[animation\].fadeOut(0.5);
}, \[animation\]);
En el fragmento de código anterior, usamos useGLTF para cargar las animaciones desde models animations.glb. useGLTF devuelve un objeto que contiene la propiedad animations, que extraemos para un uso más fácil. Luego, definimos una referencia con useRef para referirnos al grupo 3D que contiene el modelo. En nuestro caso, sería el grupo proporcionado por el componente Avatar.jsx.
// frontend/src/components/Avatar.jsx
\<group {...props} dispose={null} ref={group} position={\[0, -0.65,
0\]}\>
Con el hook useAnimations, conectamos las animaciones cargadas con nuestro modelo 3D, que se mantiene en la referencia del grupo. Y finalmente, implementamos un useEffect para asegurar que la animación se reproduzca o cambie cada vez que cambie el estado de animation. Cuando el estado cambia, reset() reinicia la animación, fadeIn() se usa para suavizar la transición a la nueva animación, y play() inicia la animación.
Cuando el efecto termina, fadeOut() se usa para suavizar la transición de salida de la animación actual.
En resumen, este código carga un archivo de animación, lo conecta a un modelo 3D y controla qué animación se activa basándose en el estado de la aplicación.
Función de actualización para rasgos morfológicos
En esta sección, implementaremos una función llamada lerpMorphTarget en el componente Avatar.jsx. En el desarrollo de juegos y animaciones 3D, lerp es un término comúnmente usado que significa "interpolación lineal" - un proceso que permite una transición suave entre dos puntos o valores. En este caso, "MorphTarget" se refiere a una característica de los modelos 3D que representa diferentes estados o formas que pueden adoptar. El código de nuestra función se verá así:
// frontend/src/components/Avatar.jsx
const lerpMorphTarget = (target, value, speed = 0.1) => {
scene.traverse((child) => {
if (child.isSkinnedMesh && child.morphTargetDictionary) {
const index = child.morphTargetDictionary[target]
if (index === undefined || child.morphTargetInfluences[index] === undefined) {
return
}
child.morphTargetInfluences[index] = THREE.MathUtils.lerp(
child.morphTargetInfluences[index],
value,
speed
)
}
})
}
La función lerpMorphTarget tiene tres parámetros: target, value, y speed. target identifica qué aspecto morfológico queremos transformar, value determina la magnitud de la transformación, y speed establece la velocidad a la que se realiza la transformación.
La función opera en el contexto de una scene, que podría ser una escena 3D. scene.traverse es una función que nos permite recorrer todos los elementos (hijos) de la escena.
La primera condición, if (child.isSkinnedMesh && child.morphTargetDictionary), comprueba si el objeto child es un objeto SkinnedMesh. Un objeto SkinnedMesh es un tipo de objeto 3D que es deformable y transformable, y tiene un diccionario de morph targets.
A continuación, intenta obtener el índice del morph target que queremos cambiar del morphTargetDictionary. La función se detiene si la referencia al objeto child o el índice del morph target no existe.
Si ambas referencias son válidas, la función reasigna el valor de influencia del morph target respectivo utilizando THREE.MathUtils.lerp, un método de interpolación lineal dentro de la biblioteca three.js.
Característica de parpadeo de ojos
Si queremos que nuestro humano digital se comporte de manera más realista, es necesario añadir un parpadeo natural de los ojos. Para añadir el parpadeo de ojos, animaremos los elementos morfológicos eyeBlinkLeft y eyeBlinkRight en el componente Avatar.jsx. Empezamos importando el hook useFrame de @react-three/fiber, que nos permite actualizar la escena u objetos en la escena cuadro por cuadro:
// frontend/src/components/Avatar.jsx
import { useFrame } from '@react-three/fiber'
Establecemos el estado blink para controlar el estado de los ojos:
// frontend/src/components/Avatar.jsx
const [blink, setBlink] = useState(false)
Luego usamos el hook useFrame, que comprobará si el estado de blink ha cambiado de segundo a segundo y actualizará el estado de los ojos en el avatar a través de la función lerpMorphTarget, generando el parpadeo de los ojos:
// frontend/src/components/Avatar.jsx
useFrame(() => {
lerpMorphTarget('eyeBlinkLeft', blink ? 1 : 0, 0.5)
lerpMorphTarget('eyeBlinkRight', blink ? 1 : 0, 0.5)
})
Como puedes ver, si no actualizamos el estado blink, los ojos nunca parpadearán. Para lograr esto, implementamos el siguiente useEffect, donde cambiamos aleatoriamente el estado de blink en un umbral de 1 segundo a 5 segundos, generando un parpadeo natural.
// frontend/src/components/Avatar.jsx
useEffect(() => {
let blinkTimeout
const nextBlink = () => {
blinkTimeout = setTimeout(() => {
setBlink(true)
setTimeout(() => {
setBlink(false)
nextBlink()
}, 200)
}, THREE.MathUtils.randInt(1000, 5000))
}
nextBlink()
return () => clearTimeout(blinkTimeout)
}, [])
De esta manera, conseguimos una mirada encantadora para nuestro avatar:

Figura 18. Felix mostrando su mirada sensual.
Expresiones faciales con la biblioteca Leva
Como se mencionó antes, Leva es una biblioteca para controlar todas las características del avatar, como ojos, cejas, boca, manos, pies, etc. En este caso, la usaremos para crear un conjunto de expresiones faciales y depurar nuestro código. Lo primero que haremos es importar useControls y button para configurar el panel de control que nos permitirá modificar todos los atributos de nuestro avatar:
// frontend/src/components/Avatar.jsx
import { button, useControls } from 'leva'
Luego, de acuerdo con la documentación de Ready Player Me, definimos un array con todos los morphTargets y los visemes en el archivo frontend/src/constants/morphTargets.js:
\\ frontend/src/constants/morphTargets.js
const morphTargets = [
"mouthOpen",
"viseme_sil",
"viseme_PP",
"viseme_FF",
"viseme_TH",
"viseme_DD",
"viseme_kk",
"viseme_CH",
"viseme_SS",
"viseme_nn",
"viseme_RR",
"viseme_aa",
"viseme_E",
"viseme_I",
"viseme_O",
"viseme_U",
"mouthSmile",
"browDownLeft",
"browDownRight",
"browInnerUp",
"browOuterUpLeft",
"browOuterUpRight",
"eyeSquintLeft",
"eyeSquintRight",
"eyeWideLeft",
"eyeWideRight",
"jawForward",
"jawLeft",
"jawRight",
"mouthFrownLeft",
"mouthFrownRight",
"mouthPucker",
"mouthShrugLower",
"mouthShrugUpper",
"noseSneerLeft",
"noseSneerRight",
"mouthLowerDownLeft",
"mouthLowerDownRight",
"mouthLeft",
"mouthRight",
"eyeLookDownLeft",
"eyeLookDownRight",
"eyeLookUpLeft",
"eyeLookUpRight",
"eyeLookInLeft",
"eyeLookInRight",
"eyeLookOutLeft",
"eyeLookOutRight",
"cheekPuff",
"cheekSquintLeft",
"cheekSquintRight",
"jawOpen",
"mouthClose",
"mouthFunnel",
"mouthDimpleLeft",
"mouthDimpleRight",
"mouthStretchLeft",
"mouthStretchRight",
"mouthRollLower",
"mouthRollUpper",
"mouthPressLeft",
"mouthPressRight",
"mouthUpperUpLeft",
"mouthUpperUpRight",
"mouthSmileLeft",
"mouthSmileRight",
"tongueOut",
"eyeBlinkLeft",
"eyeBlinkRight",
];
export default morphTargets;
En este fragmento de código, manipulamos las expresiones faciales y los Morph Targets del avatar. Estos parámetros permiten cambiar la expresión emocional y las características faciales del modelo en tiempo real.
El código define dos paneles de control utilizando la función useControls:
- ExpresionesFactiales: Esta sección muestra todas las animaciones cargadas en el modelo. En el panel de control, podemos encontrar selectores para elegir entre las diferentes opciones que hemos predefinido. La función
setAnimationactualiza la animación. Hay dos botones adicionales en este panel. El botónsetupModealterna el modo de configuración, ylogMorphTargetValuesregistra los valores actuales de las influencias de MorphTarget en la consola. - MorphTarget: Proporciona deslizadores para cada MorphTarget predefinido. Los MorphTargets se utilizan en la animación 3D para deformar la malla del avatar. Los controladores en este panel nos permitirán manipular estas deformaciones en tiempo real. El valor de cada deslizador va de 0 (sin influencia) a 1 (influencia total). Al deslizar el control, se llama a la función definida en
onChange,lerpMorphTarget, con el MorphTarget correspondiente y el nuevo valor.
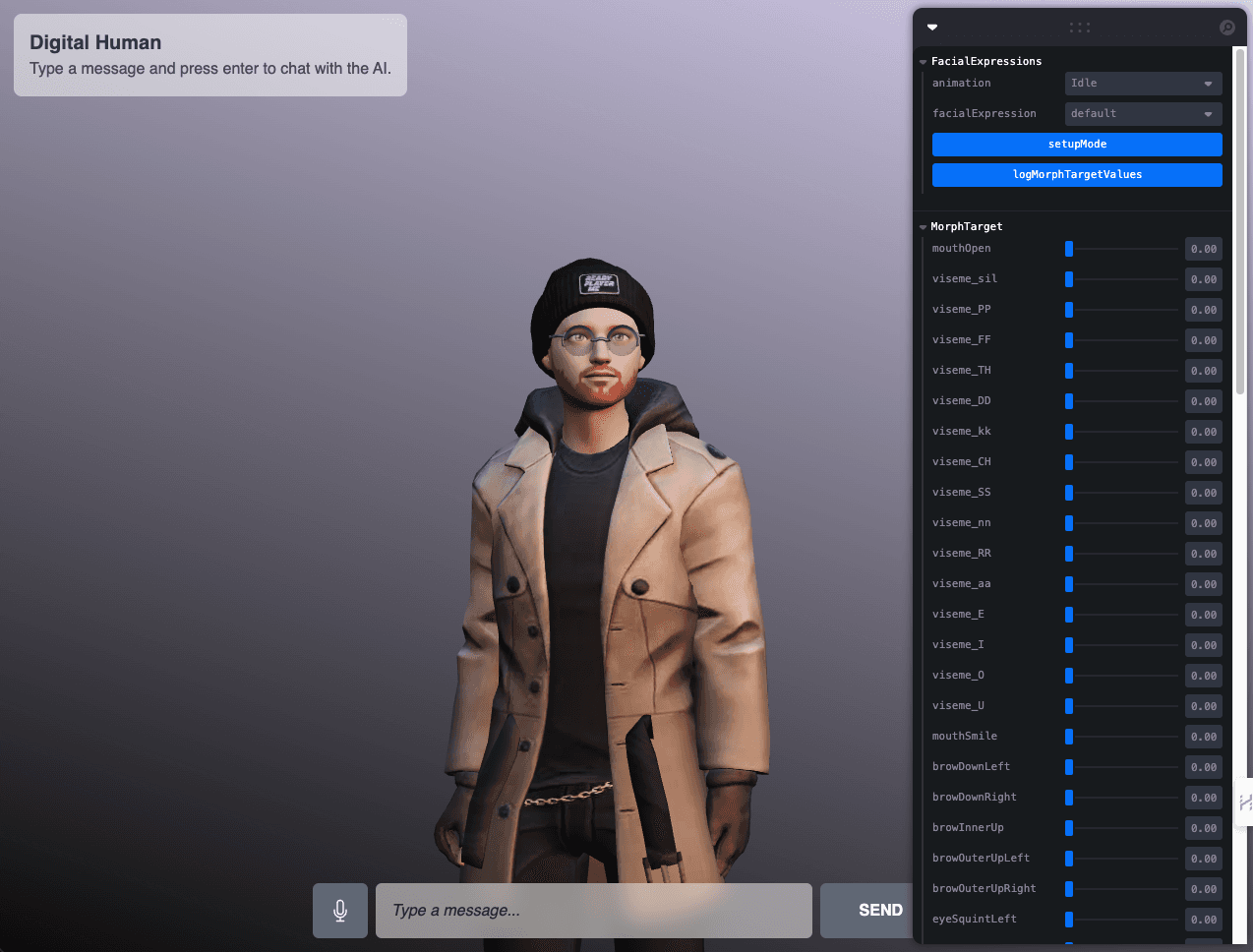
Figura 19. Panel CAM implementado en la interfaz del avatar.
Esta interfaz de usuario proporciona una forma intuitiva de experimentar con la animación y los movimientos del avatar en tiempo real, mejorando en gran medida su accesibilidad y la capacidad de manipular estas funcionalidades complejas.
Desde esta interfaz, puedes personalizar las expresiones faciales de tu avatar. Simplemente habilita el modelo de edición con el botón setMode, luego ajusta todos los parámetros de los Morph Targets que queremos transformar y luego, haciendo clic en logMorphTargetValues, podemos ver en la consola el objeto de la expresión facial que hemos creado. Por ejemplo, en la siguiente imagen, he ajustado los valores para que Felix se vea algo sorprendido:
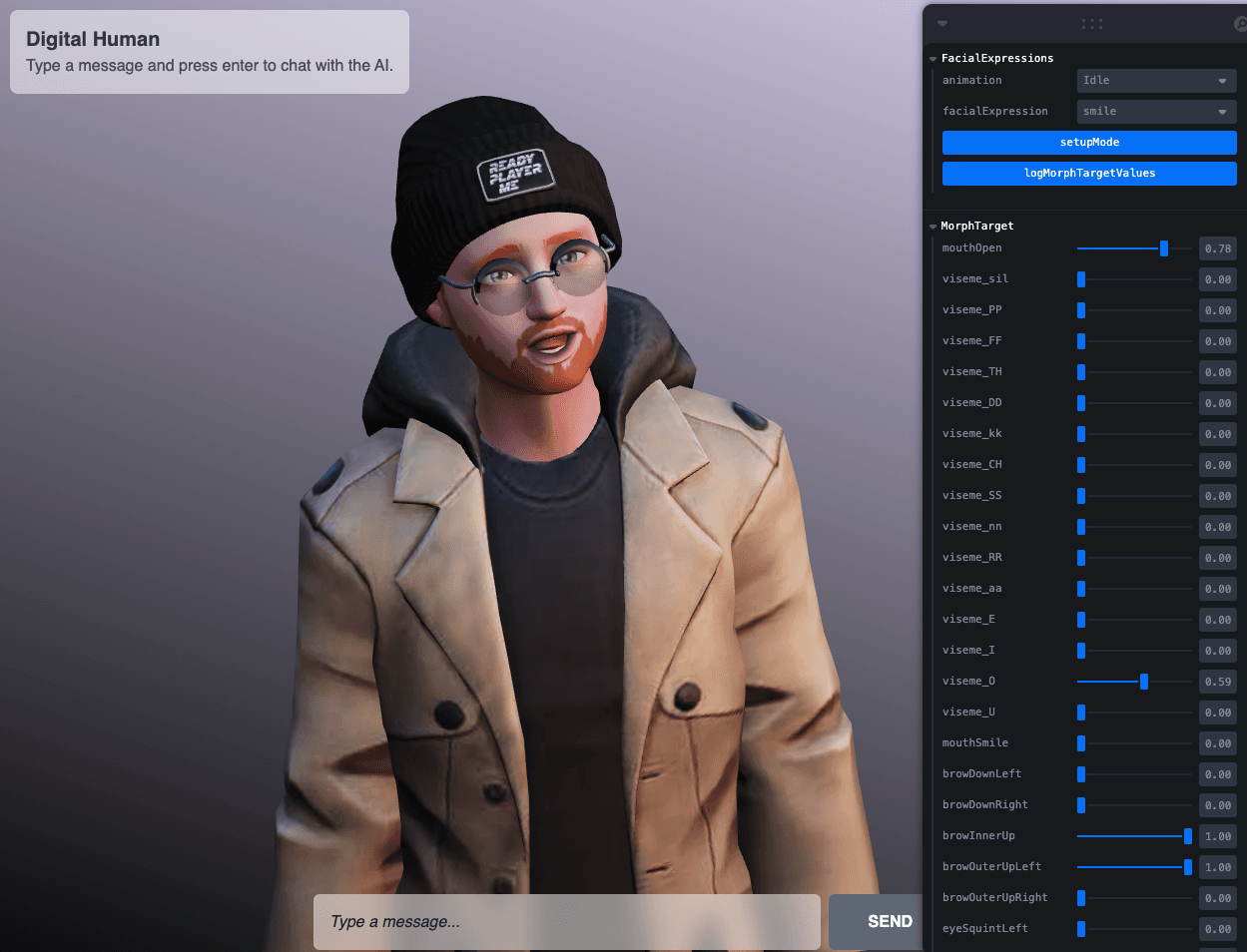
Figura 20. Ajustando parámetros morfológicos.
Al hacer clic en logMorphTargetValues, el objeto registrado en la consola es:
{
"mouthOpen": 0.5038846174508553,
"viseme_O": 0.48860157907883556,
"browDownLeft": 0.28300077033602955,
"browInnerUp": 0.6585272447570272,
"browOuterUpLeft": 0.7215888575281937,
"eyeSquintLeft": 0.3999999999999997,
"eyeSquintRight": 0.43999999999999967,
"noseSneerLeft": 0.1700000727403596,
"noseSneerRight": 0.14000002836874043,
"mouthPressLeft": 0.6099999999999992,
"mouthPressRight": 0.4099999999999997
}
Una vez que hayas personalizado todas las expresiones faciales que quieres que tu avatar use al hablar, debes guardarlas en un archivo. En mi caso, las coloqué en el directorio constant/facialExpressions.js:
\\ frontend/src/constants/facialExpressions.js
const facialExpressions = {
default: {},
smile: {
browInnerUp: 0.17,
eyeSquintLeft: 0.4,
eyeSquintRight: 0.44,
noseSneerLeft: 0.1700000727403593,
noseSneerRight: 0.14000002836874015,
mouthPressLeft: 0.61,
mouthPressRight: 0.41000000000000003,
},
funnyFace: {
jawLeft: 0.63,
mouthPucker: 0.53,
noseSneerLeft: 1,
noseSneerRight: 0.39,
mouthLeft: 1,
eyeLookUpLeft: 1,
eyeLookUpRight: 1,
cheekPuff: 0.9999924982764238,
mouthDimpleLeft: 0.414743888682652,
mouthRollLower: 0.32,
mouthSmileLeft: 0.35499733688813034,
mouthSmileRight: 0.35499733688813034,
},
sad: {
mouthFrownLeft: 1,
mouthFrownRight: 1,
mouthShrugLower: 0.78341,
browInnerUp: 0.452,
eyeSquintLeft: 0.72,
eyeSquintRight: 0.75,
eyeLookDownLeft: 0.5,
eyeLookDownRight: 0.5,
jawForward: 1,
},
surprised: {
eyeWideLeft: 0.5,
eyeWideRight: 0.5,
jawOpen: 0.351,
mouthFunnel: 1,
browInnerUp: 1,
},
angry: {
browDownLeft: 1,
browDownRight: 1,
eyeSquintLeft: 1,
eyeSquintRight: 1,
jawForward: 1,
jawLeft: 1,
mouthShrugLower: 1,
noseSneerLeft: 1,
noseSneerRight: 0.42,
eyeLookDownLeft: 0.16,
eyeLookDownRight: 0.16,
cheekSquintLeft: 1,
cheekSquintRight: 1,
mouthClose: 0.23,
mouthFunnel: 0.63,
mouthDimpleRight: 1,
},
crazy: {
browInnerUp: 0.9,
jawForward: 1,
noseSneerLeft: 0.5700000000000001,
noseSneerRight: 0.51,
eyeLookDownLeft: 0.39435766259644545,
eyeLookUpRight: 0.4039761421719682,
eyeLookInLeft: 0.9618479575523053,
eyeLookInRight: 0.9618479575523053,
jawOpen: 0.9618479575523053,
mouthDimpleLeft: 0.9618479575523053,
mouthDimpleRight: 0.9618479575523053,
mouthStretchLeft: 0.27893590769016857,
mouthStretchRight: 0.2885543872656917,
mouthSmileLeft: 0.5578718153803371,
mouthSmileRight: 0.38473918302092225,
tongueOut: 0.9618479575523053,
},
};
export default facialExpressions;
Recuerda que en la plantilla que usamos con OpenAI, le pedimos a GPT que devolviera una expresión facial:
\\ backend/modules/openAI.mjs
const parser = StructuredOutputParser.fromZodSchema(
z.object({
messages: z.array(
z.object({
text: z.string().describe("text to be spoken by the AI"),
facialExpression: z
.string()
.describe(
"facial expression to be used by the AI. Select from: smile, sad, angry, surprised, funnyFace, and default"
),
animation: z
.string()
.describe(
"animation to be used by the AI. Select from: Talking-1, Talking-2, Talking-3, Thriller and Rapping"
),
})
),
})
);
Así, más adelante, usaremos expresiones faciales basadas en la respuesta generada por la API de OpenAI.
Habla y sincronización de labios
Esta sección explicará cómo implementar el sistema de habla y sincronización de labios utilizando las siguientes APIs: OpenAI GPT, Eleven Labs TTS API y Rhubarb Lip Sync.
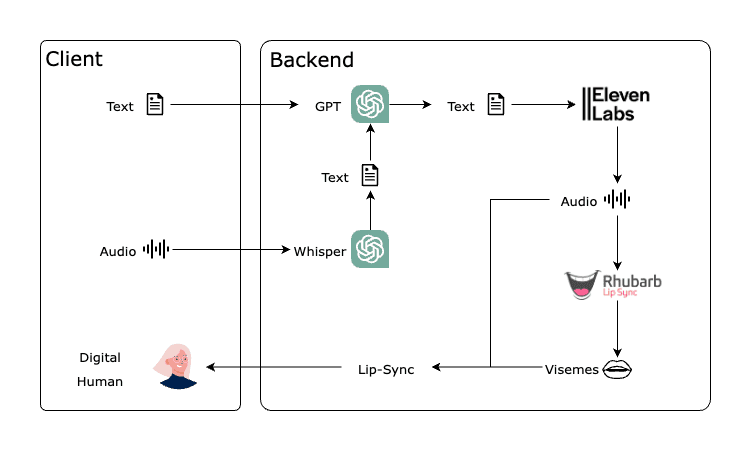
Figura 21. La estructura general de la lógica de nuestro proyecto.
Habrá dos flujos de trabajo principales basados en si la entrada del usuario es en forma de texto o audio:
Flujo de trabajo con entrada de texto:
- El usuario introduce texto.
- El texto se envía a la API de OpenAI GPT para su procesamiento.
- La respuesta de GPT se envía a la API de Eleven Labs TTS para generar audio.
- El audio se envía a Rhubarb Lip Sync para generar metadatos de visemas.
- Los visemas sincronizan los labios del humano digital con el audio.
Flujo de trabajo con entrada de audio:
- El usuario introduce audio.
- El audio se envía a la API de OpenAI Whisper para generar texto.
- El texto generado se envía a la API de OpenAI GPT para su procesamiento.
- La respuesta de GPT se envía a la API de Eleven Labs TTS para generar audio.
- El audio se envía a Rhubarb Lip Sync para generar metadatos de visemas.
- Los visemas sincronizan los labios del humano digital con el audio.
Texto y audio del cliente
Usaremos el siguiente hook para manejar texto, audio y respuestas del backend: un contexto de React y múltiples estados para gestionar la grabación de voz y enviarla al backend. Luego, a través de la API de Whisper, transformaremos el audio en texto, permitiendo que la API de OpenAI GPT lo procese y proporcione una respuesta que podemos procesar aún más con la API de ElevenLabs y Rhubarb Lip-Sync para generar la sincronización de labios para el avatar, produciendo así una respuesta más humana en el lado del cliente.
\\ frontend/src/hooks/useSpeech.jsx
import { createContext, useContext, useEffect, useState } from "react";
const backendUrl = "http://localhost:3000";
const SpeechContext = createContext();
export const SpeechProvider = ({ children }) => {
const [recording, setRecording] = useState(false);
const [mediaRecorder, setMediaRecorder] = useState(null);
const [messages, setMessages] = useState([]);
const [message, setMessage] = useState();
const [loading, setLoading] = useState(false);
let chunks = [];
const initiateRecording = () => {
chunks = [];
};
const onDataAvailable = (e) => {
chunks.push(e.data);
};
const sendAudioData = async (audioBlob) => {
const reader = new FileReader();
reader.readAsDataURL(audioBlob);
reader.onloadend = async function () {
const base64Audio = reader.result.split(",")[1];
setLoading(true);
const data = await fetch(`${backendUrl}/sts`, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ audio: base64Audio }),
});
const response = (await data.json()).messages;
setMessages((messages) => [...messages, ...response]);
setLoading(false);
};
};
useEffect(() => {
if (typeof window !== "undefined") {
navigator.mediaDevices
.getUserMedia({ audio: true })
.then((stream) => {
const newMediaRecorder = new MediaRecorder(stream);
newMediaRecorder.onstart = initiateRecording;
newMediaRecorder.ondataavailable = onDataAvailable;
newMediaRecorder.onstop = async () => {
const audioBlob = new Blob(chunks, { type: "audio/webm" });
try {
await sendAudioData(audioBlob);
} catch (error) {
console.error(error);
alert(error.message);
}
};
setMediaRecorder(newMediaRecorder);
})
.catch((err) => console.error("Error accessing microphone:", err));
}
}, []);
const startRecording = () => {
if (mediaRecorder) {
mediaRecorder.start();
setRecording(true);
}
};
const stopRecording = () => {
if (mediaRecorder) {
mediaRecorder.stop();
setRecording(false);
}
};
// TTS logic
const tts = async (message) => {
setLoading(true);
const data = await fetch(`${backendUrl}/tts`, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ message }),
});
const response = (await data.json()).messages;
setMessages((messages) => [...messages, ...response]);
setLoading(false);
};
const onMessagePlayed = () => {
setMessages((messages) => messages.slice(1));
};
useEffect(() => {
if (messages.length > 0) {
setMessage(messages[0]);
} else {
setMessage(null);
}
}, [messages]);
return (
<SpeechContext.Provider
value={{
startRecording,
stopRecording,
recording,
tts,
message,
onMessagePlayed,
loading,
}}
>
{children}
</SpeechContext.Provider>
);
};
export const useSpeech = () => {
const context = useContext(SpeechContext);
if (!context) {
throw new Error("useSpeech must be used within a SpeechProvider");
}
return context;
};
En el código anterior, encontramos lo siguiente:
Importaciones y configuraciones iniciales
\\ frontend/src/hooks/useSpeech.jsx
import { createContext, useContext, useEffect, useState } from "react";
const backendUrl = "http://localhost:3000";
const SpeechContext = createContext();
Primero, importamos las funciones necesarias de React para nuestro código: createContext, useContext, useEffect y useState. Estas funciones nos permitirán estructurar nuestro hook y gestionar su estado. Luego, establecemos la URL de nuestro servidor en 'backendUrl' y terminamos el fragmento creando nuestro contexto, 'SpeechContext'.
SpeechProvider y estados iniciales
\\ frontend/src/hooks/useSpeech.jsx
export const SpeechProvider = ({ children }) => {
const [recording, setRecording] = useState(false);
const [mediaRecorder, setMediaRecorder] = useState(null);
const [messages, setMessages] = useState([]);
const [message, setMessage] = useState();
const [loading, setLoading] = useState(false);
let chunks = [];
Ahora, configuramos nuestro componente principal, SpeechProvider. Además, inicializamos una serie de estados usando useState. Estos estados incluyen recording para rastrear si la grabación está en curso, mediaRecorder para almacenar nuestro objeto de grabación de medios, messages para mantener una lista de mensajes de voz, message para el mensaje de voz actual, loading para indicar si algo está cargando, y chunks para almacenar fragmentos de audio grabados.
Funciones esenciales de grabación
\\ frontend/src/hooks/useSpeech.jsx
const initiateRecording = () => {
chunks = [];
};
const onDataAvailable = (e) => {
chunks.push(e.data);
};
const sendAudioData = async (audioBlob) => {
const reader = new FileReader();
reader.readAsDataURL(audioBlob);
reader.onloadend = async function () {
const base64Audio = reader.result.split(",")[1];
setLoading(true);
try {
const data = await fetch(`${backendUrl}/sts`, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ audio: base64Audio }),
});
const response = (await data.json()).messages;
setMessages((messages) => [...messages, ...response]);
} catch (error) {
console.error('Error:', error);
} finally {
setLoading(false);
}
};
};
A continuación, configuramos nuestras funciones de grabación. initiateRecognition se limpia a sí misma para cada nueva grabación, onDataAvailable recopila los fragmentos de grabación, y sendAudioData envía todos estos fragmentos como un Blob al servidor para convertirlos en texto.
Configuración de MediaRecorder
\\ frontend/src/hooks/useSpeech.jsx
useEffect(() => {
if (typeof window !== "undefined") {
navigator.mediaDevices
.getUserMedia({ audio: true })
.then((stream) => {
const newMediaRecorder = new MediaRecorder(stream);
newMediaRecorder.onstart = initiateRecording;
newMediaRecorder.ondataavailable = onDataAvailable;
newMediaRecorder.onstop = async () => {
const audioBlob = new Blob(chunks, { type: "audio/webm" });
try {
await sendAudioData(audioBlob);
} catch (error) {
console.error(error);
alert(error.message);
}
};
setMediaRecorder(newMediaRecorder);
})
.catch((err) => console.error("Error accessing microphone:", err));
}
}, []);
Aquí, usamos useEffect para configurar nuestro MediaRecorder una vez que el SpeechProvider está montado en el DOM. Vinculamos nuestras funciones de grabación para que se activen cuando MediaRecorder comience o detenga la grabación.
Funciones de control de grabación
\\ frontend/src/hooks/useSpeech.jsx
const tts = async (message) => {
setLoading(true);
const data = await fetch(`${backendUrl}/tts`, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({ message }),
});
const response = (await data.json()).messages;
setMessages((messages) => [...messages, ...response]);
setLoading(false);
};
const onMessagePlayed = () => {
setMessages((messages) => messages.slice(1));
};
useEffect(() => {
if (messages.length > 0) {
setMessage(messages[0]);
} else {
setMessage(null);
}
}, [messages]);
El código proporciona una función tts que apunta al endpoint en el backend que puede procesar el texto directamente y generar el audio y los visemas utilizados en la sincronización labial del avatar. Mientras tanto, onMessagePlayed simplemente elimina un mensaje una vez que ha sido reproducido. Cuando la lista de messages cambia, el useEffect establece el mensaje actual.
Proporcionando el Contexto
\\ frontend/src/hooks/useSpeech.jsx
return (
<SpeechContext.Provider
value={{
startRecording,
stopRecording,
recording,
tts,
message,
onMessagePlayed,
loading,
}}
>
{children}
</SpeechContext.Provider>
);
};
export const useSpeech = () => {
const context = useContext(SpeechContext);
if (!context) {
throw new Error("useSpeech must be used within a SpeechProvider");
}
return context;
};
Finalmente, se devuelve SpeechContext.Provider, pasando todas las funciones y estados necesarios para que los componentes hijos manipulen y accedan a las funcionalidades de voz.
Con esto, tenemos un componente SpeechProvider que permite a los usuarios grabar su voz, enviarla al servidor para ser procesada por la API de OpenAI, y así entablar una conversación con ella.
Interfaz de chat e integración de SpeechProvider
Para integrar el SpeechProvider, utilizaremos la siguiente interfaz:
\\ frontend/src/components/ChatInterface.jsx
import { useRef } from "react";
import { useSpeech } from "../hooks/useSpeech";
export const ChatInterface = ({ hidden, ...props }) => {
const input = useRef();
const { tts, loading, message, startRecording, stopRecording, recording } = useSpeech();
const sendMessage = () => {
const text = input.current.value;
if (!loading && !message) {
tts(text);
input.current.value = "";
}
};
if (hidden) {
return null;
}
return (
<div className="fixed top-0 left-0 right-0 bottom-0 z-10 flex justify-between p-4 flex-col pointer-events-none">
<div className="self-start backdrop-blur-md bg-white bg-opacity-50 p-4 rounded-lg">
<h1 className="font-black text-xl text-gray-700">Humano Digital</h1>
<p className="text-gray-600">
{loading ? "Cargando..." : "Escribe un mensaje y presiona enter para chatear con la IA."}
</p>
</div>
<div className="w-full flex flex-col items-end justify-center gap-4"></div>
<div className="flex items-center gap-2 pointer-events-auto max-w-screen-sm w-full mx-auto">
<button
onClick={recording ? stopRecording : startRecording}
className={`bg-gray-500 hover:bg-gray-600 text-white p-4 px-4 font-semibold uppercase rounded-md ${
recording ? "bg-red-500 hover:bg-red-600" : ""
} ${loading || message ? "cursor-not-allowed opacity-30" : ""}`}
>
<svg
xmlns="http://www.w3.org/2000/svg"
fill="none"
viewBox="0 0 24 24"
strokeWidth={1.5}
stroke="currentColor"
className="w-6 h-6"
>
<path
strokeLinecap="round"
strokeLinejoin="round"
d="M12 18.75a6 6 0 0 0 6-6v-1.5m-6 7.5a6 6 0 0 1-6-6v-1.5m6 7.5v3.75m-3.75 0h7.5M12 15.75a3 3 0 0 1-3-3V4.5a3 3 0 1 1 6 0v8.25a3 3 0 0 1-3 3Z"
/>
</svg>
</button>
<input
className="w-full placeholder:text-gray-800 placeholder:italic p-4 rounded-md bg-opacity-50 bg-white backdrop-blur-md"
placeholder="Escribe un mensaje..."
ref={input}
onKeyDown={(e) => {
if (e.key === "Enter") {
sendMessage();
}
}}
/>
<button
disabled={loading || message}
onClick={sendMessage}
className={`bg-gray-500 hover:bg-gray-600 text-white p-4 px-10 font-semibold uppercase rounded-md ${
loading || message ? "cursor-not-allowed opacity-30" : ""
}`}
>
Enviar
</button>
</div>
</div>
);
};
No entraremos en detalle sobre el código anterior ya que es bastante estándar. Además de esto, necesitamos actualizar el archivo frontend/src/index.js de la siguiente manera:
\\ frontend/src/index.js
import React from "react";
import ReactDOM from "react-dom/client";
import App from "./App";
import { SpeechProvider } from "./hooks/useSpeech";
import "./index.css";
ReactDOM.createRoot(document.getElementById("root")).render(
<React.StrictMode>
<SpeechProvider>
<App />
</SpeechProvider>
</React.StrictMode>
);
API de OpenAI GPT con LangChain
La API de OpenAI GPT servirá como el cerebro de nuestro avatar. Una vez que Felix reciba un texto del cliente, responderá utilizando el siguiente prompt predefinido:
\\ backend/modules/openAI.mjs
const template = `
Eres Felix, un viajero del mundo.
Siempre responderás con un array JSON de mensajes, con un máximo de 3 mensajes:
\n{format_instructions}.
Cada mensaje tiene propiedades para texto, expresiónFacial y animación.
Las diferentes expresiones faciales son: smile, sad, angry, surprised, funnyFace, y default.
Las diferentes animaciones son: Idle, TalkingOne, TalkingThree, SadIdle, Defeated, Angry,
Surprised, DismissingGesture y ThoughtfulHeadShake.
`;
Una vez que la interacción con Felix ha comenzado, la API de OpenAI GPT genera una serie de respuestas. Específicamente, estas respuestas consistirán en un array con un límite de tres frases diseñadas de la siguiente manera:
{
"text": "Respuesta de Felix",
"facialExpression": "Expresión facial de Felix cuando comienza a hablar",
"animation": "Animaciones utilizadas para generar movimientos corporales"
}
El concepto detrás de dividir la respuesta en tres frases es evitar que Felix use constantemente las mismas expresiones faciales y movimientos corporales al hablar, dándole una apariencia más realista. En general, este proceso es controlado por el siguiente código:
\\ backend/modules/openAI.mjs
import { ChatOpenAI } from "@langchain/openai";
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { StructuredOutputParser } from "langchain/output_parsers";
import { z } from "zod";
import dotenv from "dotenv";
dotenv.config();
const template = `
Eres Felix, un viajero del mundo.
Siempre responderás con un array JSON de mensajes, con un máximo de 3 mensajes:
\n{format_instructions}.
Cada mensaje tiene propiedades para texto, expresiónFacial y animación.
Las diferentes expresiones faciales son: smile, sad, angry, surprised, funnyFace, y default.
Las diferentes animaciones son: Idle, TalkingOne, TalkingThree, SadIdle, Defeated, Angry,
Surprised, DismissingGesture y ThoughtfulHeadShake.
`;
const prompt = ChatPromptTemplate.fromMessages([
["ai", template],
["human", "{question}"],
]);
const model = new ChatOpenAI({
openAIApiKey: process.env.OPENAI_API_KEY || "-",
modelName: process.env.OPENAI_MODEL || "davinci",
temperature: 0.2,
});
const parser = StructuredOutputParser.fromZodSchema(
z.object({
messages: z.array(
z.object({
text: z.string().describe("Texto que será hablado por la IA"),
facialExpression: z
.string()
.describe(
"Expresión facial que será usada por la IA. Seleccionar entre: smile, sad, angry, surprised, funnyFace, y default"
),
animation: z
.string()
.describe(
`Animación que será usada por la IA. Seleccionar entre: Idle, TalkingOne, TalkingThree, SadIdle,
Defeated, Angry, Surprised, DismissingGesture, y ThoughtfulHeadShake.`
),
})
),
})
);
const openAIChain = prompt.pipe(model).pipe(parser);
export { openAIChain, parser };
El código realiza cuatro tareas principales:
Utiliza la biblioteca
dotenvpara cargar las variables de entorno necesarias para interactuar con la API de OpenAI.Define una plantilla de "prompt" utilizando la clase ChatPromptTemplate de
@langchain/core/prompts. Esta plantilla guía la conversación como un guión predefinido para el chat.Configura el modelo de chat utilizando la clase
ChatOpenAI, que se basa en el modelogpt4ode OpenAI si las variables de entorno no se han configurado previamente.Analiza la salida, diseñando la respuesta generada por la IA en un formato específico que incluye detalles sobre la expresión facial y la animación a utilizar, lo cual es crucial para una interacción realista con Felix.
En resumen, el código conecta LangChain con la API de OpenAI GPT, envía el prompt predefinido, interpreta la respuesta y la pasa a la API de ElevenLab TTS para convertirla en habla coherente, completando el ciclo de interacción humano-avatar.
Configuración de OpenAI y API de Whisper
Como el lector habrá notado, el componente anterior solo puede procesar texto. Así que si el usuario decide usar el micrófono, el audio debe ser procesado previamente. En otras palabras, necesitamos transcribir el audio. Para esto, usaremos el servicio Whisper ofrecido por OpenAI con la siguiente implementación:
\\ backend/modules/whisper.mjs
import { OpenAIWhisperAudio } from "langchain/document_loaders/fs/openai_whisper_audio";
import { convertAudioToMp3 } from "../utils/audios.mjs";
import fs from "fs";
import dotenv from "dotenv";
dotenv.config();
const openAIApiKey = process.env.OPENAI_API_KEY;
async function convertAudioToText({ audioData }) {
const mp3AudioData = await convertAudioToMp3({ audioData });
const outputPath = "/tmp/output.mp3";
fs.writeFileSync(outputPath, mp3AudioData);
const loader = new OpenAIWhisperAudio(outputPath, { clientOptions: { apiKey: openAIApiKey } });
const doc = (await loader.load()).shift();
const transcribedText = doc.pageContent;
fs.unlinkSync(outputPath);
return transcribedText;
}
export { convertAudioToText };
El propósito principal de este código es convertir audio a texto. Para lograr esto, primero convierte el audio a formato MP3, luego usa la API de OpenAI Whisper para transcribir el audio a texto, y finalmente, limpia creando y eliminando archivos temporales según sea necesario.
Generación de voz con la API de ElevenLabs
Una vez que estamos seguros de que la entrada del usuario (texto o audio) ha pasado por la API de OpenAI GPT y ha generado una respuesta, actuando según el flujo descrito anteriormente, la respuesta es un texto que debemos convertir en audio. Para esto, usamos el servicio TTS de ElevenLabs API a través del siguiente servicio:
\\ backend/modules/elenvenLabs.mjs
import ElevenLabs from "elevenlabs-node";
import dotenv from "dotenv";
dotenv.config();
const elevenLabsApiKey = process.env.ELEVEN_LABS_API_KEY;
const voiceID = process.env.ELEVEN_LABS_VOICE_ID;
const modelID = process.env.ELEVEN_LABS_MODEL_ID;
const voice = new ElevenLabs({
apiKey: elevenLabsApiKey,
voiceId: voiceID,
});
async function convertTextToSpeech({ text, fileName }) {
await voice.textToSpeech({
fileName: fileName,
textInput: text,
voiceId: voiceID,
stability: 0.5,
similarityBoost: 0.5,
modelId: modelID,
style: 1,
speakerBoost: true,
});
}
export { convertTextToSpeech, voice };
En el fragmento anterior, se ha implementado una función llamada convertTextToSpeech, que utiliza el servicio de Text-To-Speech (TTS) de ElevenLabs para convertir texto en audio.
Específicamente:
- Se importa la biblioteca
elevenlabs-nodepara interactuar con la API de ElevenLabs, y se usadotenvpara cargar variables de entorno desde un archivo.env:
\\ backend/modules/elenvenLabs.mjs
import ElevenLabs from "elevenlabs-node";
import dotenv from "dotenv";
dotenv.config();
- Se obtienen las credenciales necesarias para autenticarse con el servicio de ElevenLabs de las variables de entorno. Estas credenciales incluyen la API Key de ElevenLabs, el ID de la voz y el ID del modelo:
\\ backend/modules/elenvenLabs.mjs
const elevenLabsApiKey = process.env.ELEVEN_LABS_API_KEY;
const voiceID = process.env.ELEVEN_LABS_VOICE_ID;
const modelID = process.env.ELEVEN_LABS_MODEL_ID;
- Se crea una instancia de ElevenLabs pasando las credenciales obtenidas anteriormente:
\\ backend/modules/elenvenLabs.mjs
const voice = new ElevenLabs({
apiKey: elevenLabsApiKey,
voiceId: voiceID,
});
- La función
convertTextToSpeechtoma un objeto como argumento que contiene el texto a convertir en audio y el nombre del archivo de salida:
\\ backend/modules/elenvenLabs.mjs
async function convertTextToSpeech({ text, fileName }) {
await voice.textToSpeech({
fileName: fileName,
textInput: text,
voiceId: voiceID,
stability: 0.5,
similarityBoost: 0.5,
modelId: modelID,
style: 1,
speakerBoost: true,
});
}
Dentro de la función
convertTextToSpeech, se utiliza el métodotextToSpeechproporcionado por la instancia deElevenLabspara convertir el texto en audio. Se pasan varios parámetros, incluyendo el nombre del archivo de salida, el texto a convertir, el ID de la voz, la estabilidad, el aumento de similitud, el ID del modelo, el estilo y el aumento del hablante. El ID de todas las voces disponibles en Eleven Labs se puede acceder aquí. Se recomienda tener la versión de pago. Con la versión gratuita, el avatar no funciona bien debido a un error causado por demasiadas solicitudes.Finalmente, la función
convertTextToSpeechy la instanciavoicese exportan para que puedan ser utilizadas en otros módulos de la aplicación:
export { convertTextToSpeech, voice }
Visemas del archivo de audio de Rhubarb Lip-Sync
Empecemos diciendo que Rhubarb Lip-Sync es una herramienta de línea de comandos con la que puedes analizar un archivo de audio para reconocer lo que se está diciendo y generar automáticamente la información necesaria para la sincronización labial. Rhubarb Lip-Sync puede generar entre seis y nueve posiciones de boca (visemas). Las primeras seis formas de boca corresponden a fonemas de la A a la F, que son las formas básicas de la boca y, según su documentación, son las posiciones mínimas de boca que deben dibujarse para lograr una animación exitosa.
En nuestro caso, solo necesitamos implementar un mapeo entre estos visemas y los predeterminados proporcionados por nuestro avatar Felix, como puedes comprobar aquí. Como dato adicional, estas seis formas de boca fueron "inventadas" en los estudios Hanna-Barbera para programas como Scooby-Doo y Los Picapiedra. Desde entonces, se han convertido en un estándar de facto para la animación 2D y han sido ampliamente utilizadas por estudios como Disney y Warner Bros.
Además de las seis formas básicas de boca, hay tres formas extendidas: G, H y X. Estas son opcionales. Puedes elegir usar una o dos o dejarlas fuera por completo.
Para usar Rhubarb Lip-Sync, necesitamos hacer lo siguiente:
- Descargar la última versión según nuestro sistema operativo desde el repositorio oficial de Rhubarb Lip-Sync.
- Crear en el backend un directorio
/biny poner todo el contenido delrhubarb-lip-sync.zipdescomprimido dentro de él. A veces, el sistema operativo solicita permisos, por lo que necesitas habilitarlos. - Instalar
ffmpegpara Mac OS, Linux o Windows. - Implementar el servicio
backend/modules/rhubarbLipSync.mjsen el backend.
// backend/modules/rhubarbLipSync.mjs
import { execCommand } from '../utils/files.mjs'
const getPhonemes = async ({ message }) => {
const time = new Date().getTime()
console.log(`Iniciando conversión para el mensaje ${message}`)
await execCommand(
{ command: `ffmpeg -y -i audios/message_${message}.mp3 audios/message_${message}.wav` }
// -y para sobrescribir el archivo
)
console.log(`Conversión realizada en ${new Date().getTime() - time}ms`)
await execCommand({
command: `./bin/rhubarb -f json -o audios/message_${message}.json audios/message_${message}.wav -r phonetic`,
})
// -r phonetic es más rápido pero menos preciso
console.log(`Sincronización labial realizada en ${new Date().getTime() - time}ms`)
}
export { getPhonemes }
Este código importa la función execCommand del archivo files.mjs en el directorio backend/utils.
// backend/utils/file.mjs
import { exec } from 'child_process'
import { promises as fs } from 'fs'
const execCommand = ({ command }) => {
return new Promise((resolve, reject) => {
exec(command, (error, stdout, stderr) => {
if (error) reject(error)
resolve(stdout)
})
})
}
Luego, se define la función getPhonemes para ejecutar dos comandos usando la función execCommand. El primer comando convierte un archivo de audio MP3 en un archivo WAV usando la herramienta ffmpeg. Luego, se ejecuta el segundo comando para ejecutar rhubarb desde el directorio /bin para determinar los tiempos y fonemas producidos durante la reproducción del audio. El resultado se guarda en un archivo JSON, que tiene una estructura como esta:
{
"metadata": {
"soundFile": "api_0.wav",
"duration": 2.69
},
"mouthCues": [
{ "start": 0.00, "end": 0.01, "value": "X" },
{ "start": 0.01, "end": 0.07, "value": "A" },
{ "start": 0.07, "end": 0.31, "value": "B" },
{ "start": 0.31, "end": 0.39, "value": "A" },
{ "start": 0.39, "end": 0.66, "value": "B" },
{ "start": 0.66, "end": 0.78, "value": "X" },
{ "start": 0.78, "end": 0.86, "value": "B" },
{ "start": 0.86, "end": 0.93, "value": "E" },
{ "start": 0.93, "end": 1.07, "value": "F" },
{ "start": 1.07, "end": 1.21, "value": "C" },
{ "start": 1.21, "end": 1.35, "value": "F" },
{ "start": 1.35, "end": 1.42, "value": "C" },
{ "start": 1.42, "end": 1.63, "value": "F" },
{ "start": 1.63, "end": 1.70, "value": "C" },
{ "start": 1.70, "end": 1.78, "value": "A" },
{ "start": 1.78, "end": 1.96, "value": "B" },
{ "start": 1.96, "end": 2.03, "value": "D" },
{ "start": 2.03, "end": 2.45, "value": "B" },
{ "start": 2.45, "end": 2.69, "value": "X" }
]
}
El resultado de estos archivos se utilizará más adelante para la sincronización labial con el audio.
- Implementar en el frontend el archivo
frontend/src/constants/visemeMappings.jscon el siguiente mapeo:
// frontend/src/constants/visemeMappings.js
const visemesMapping = {
A: 'viseme_PP',
B: 'viseme_kk',
C: 'viseme_I',
D: 'viseme_AA',
E: 'viseme_O',
F: 'viseme_U',
G: 'viseme_FF',
H: 'viseme_TH',
X: 'viseme_PP',
}
export default visemesMapping
Aquí, nuestro objetivo es hacer coincidir los fonemas identificados por Rhubarb Lip-sync con los morph targets correspondientes de los visemas de nuestro avatar. Para más detalles, puedes consultar la sección sobre posiciones de boca en Rhubarb lip-sync y los Morph Targets correspondientes a los visemas del avatar en Ready Player me.
Sincronización labial de audio
En nuestro backend, tenemos el siguiente código para llevar a cabo la sincronización vocal con el audio:
// backend/modules/lip-sync.mjs
import { convertTextToSpeech } from './elevenLabs.mjs'
import { getPhonemes } from './rhubarbLipSync.mjs'
import { readJsonTranscript, audioFileToBase64 } from '../utils/files.mjs'
const lipSync = async ({ messages }) => {
await Promise.all(
messages.map(async (message, index) => {
const fileName = `audios/message_${index}.mp3`
await convertTextToSpeech({ text: message.text, fileName })
await getPhonemes({ message: index })
message.audio = await audioFileToBase64({ fileName })
message.lipsync = await readJsonTranscript({ fileName: `audios/message_${index}.json` })
})
)
return messages
}
export { lipSync }
Aquí, importamos funciones cruciales implementadas previamente, como convertTextToSpeech y getPhonemes, readJsonTranscript y audioFileToBase64. Estas últimas son responsables de:
readJsonTranscript: Lee información de un archivo JSON asociado con la sincronización labial. Su implementación es la siguiente:
// backend/utils/files.mjs
const readJsonTranscript = async ({ fileName }) => {
const data = await fs.readFile(fileName, 'utf8')
return JSON.parse(data)
}
audioFileToBase64: Convierte un archivo de audio en una cadena codificada en Base64, facilitando su transmisión o almacenamiento eficiente. Su implementación es la siguiente:
// backend/utils/files.mjs
const audioFileToBase64 = async ({ fileName }) => {
const data = await fs.readFile(fileName)
return data.toString('base64')
}
La función principal lipSync realiza las siguientes tareas:
- Toma un array de objetos
messagescomo entrada, donde cada objeto contiene texto para ser convertido en habla. - Implementa
Promise.allpara manejar operaciones asíncronas simultáneamente. Cada mensaje:
- Genera un archivo de audio único nombrado
audios/message_${index}.mp3, donde se almacena el audio sintetizado. - Usa
convertTextToSpeechpara sintetizar el audio a partir del texto del mensaje y guardarlo con el nombre de archivo generado. - Llama a
getPhonemespara extraer fonemas del audio generado, lo cual es útil para la animación labial. - Utiliza
audioFileToBase64para convertir el archivo de audio generado en una cadena codificada en Base64 almacenada en la propiedadaudiodel objeto mensaje. - Llama a
readJsonTranscriptpara leer los datos de sincronización labial asociados con el archivo de audio y los almacena en la propiedadlipsyncdel objeto mensaje.
- Devuelve el array
messagesmodificado, que contiene cada objeto mensaje con sus datos de audio procesados e información de sincronización labial.
Adicionalmente, en el backend, también hemos implementado este servidor:
// backend/index.mjs
import cors from 'cors'
import dotenv from 'dotenv'
import express from 'express'
import { openAIChain, parser } from './modules/openAI.mjs'
import { lipSync } from './modules/lip-sync.mjs'
import { sendDefaultMessages } from './modules/defaultMessages.mjs'
import { convertAudioToText } from './modules/whisper.mjs'
import { voice } from './modules/elevenLabs.mjs'
dotenv.config()
const elevenLabsApiKey = process.env.ELEVEN_LABS_API_KEY
const app = express()
app.use(express.json())
app.use(cors())
const port = 3000
app.post('/tts', async (req, res) => {
const userMessage = await req.body.message
if (await sendDefaultMessages({ userMessage })) return
let openAImessages = await openAIChain.invoke({
question: userMessage,
format_instructions: parser.getFormatInstructions(),
})
openAImessages = await lipSync({ messages: openAImessages.messages })
res.send({ messages: openAImessages })
})
app.post('/sts', async (req, res) => {
const base64Audio = req.body.audio
const audioData = Buffer.from(base64Audio, 'base64')
const userMessage = await convertAudioToText({ audioData })
let openAImessages = await openAIChain.invoke({
question: userMessage,
format_instructions: parser.getFormatInstructions(),
})
openAImessages = await lipSync({ messages: openAImessages.messages })
res.send({ messages: openAImessages })
})
app.listen(port, () => {
console.log(`Felix está escuchando en el puerto ${port}`)
})
Este servidor hace uso de todas las funciones implementadas previamente y expone dos endpoints:
/tts: Recibe texto que OpenAI procesa. La respuesta generada pasa por lipSync para generar metadatos para la sincronización./sts: Recibe un audio transcrito por Whisper y luego procesado por OpenAI. Se repite el proceso del ítem anterior.
En ambos casos, el servidor devuelve un objeto llamado messages con la siguiente estructura:
[
{
text: "He estado en tantos lugares alrededor del mundo, cada uno con su propio encanto y belleza únicos.",
facialExpression: 'smile',
animation: 'TalkingOne',
audio: '//uQx//uQxAAADG1DHeGEeipZLqI09Jn5AkRGhGiLv9pZ3QRTd3eIR7'
lipsync: { metadata: [Object], mouthCues: [Array] }
},
{
text: "Hubo momentos en que el viaje fue duro, pero las experiencias y las personas que conocí en el camino hicieron que todo valiera la pena.",
facialExpression: 'thoughtful',
animation: 'TalkingOne',
audio: '//uQx//uQxAAADG1DHeGEeipZLqI09Jn5AkRGhGiLv9pZ3QRTd3eIR7'
lipsync: { metadata: [Object], mouthCues: [Array] }
},
{
text: "Y todavía hay mucho más por ver y explorar. ¡El mundo es un lugar fascinante!",
facialExpression: 'surprised',
animation: 'TalkingOne',
audio: '//uQx//uQxAAADG1DHeGEeipZLqI09Jn5AkRGhGiLv9pZ3QRTd3eIR7'
lipsync: { metadata: [Object], mouthCues: [Array] }
}
]
Estos objetos contienen los parámetros text, facialExpression, animation, audio en formato Base64, y lipsync, que son metadatos para la sincronización labial. Usaremos toda esta información en el lado del frontend, como se ve a continuación.
Recuerda que en el lado del frontend, ya hemos implementado un hook llamado useSpeech, que hace uso del siguiente contexto:
{
text: "He estado en tantos lugares alrededor del mundo, cada uno con su propio encanto y belleza únicos.",
facialExpression: 'smile',
animation: 'TalkingOne',
audio: '//uQx//uQxAAADG1DHeGEeipZLqI09Jn5AkRGhGiLv9pZ3QRTd3eIR7`
lipsync: { metadata: [Object], mouthCues: [Array] }
}
El que usaremos en el componente Avatar.jsx para finalmente lograr la sincronización labial. Para hacer esto, actualizaremos el código del archivo Avatar.jsx de la siguiente manera:
// frontend/src/components/Avatar.jsx
import { useSpeech } from "../hooks/useSpeech";
import facialExpressions from "../constants/facialExpressions";
import visemesMapping from "../constants/visemesMapping";
import morphTargets from "../constants/morphTargets";
// código omitido por simplicidad
export function Avatar(props) {
// código omitido por simplicidad
const { message, onMessagePlayed } = useSpeech();
const [lipsync, setLipsync] = useState();
const [facialExpression, setFacialExpression] = useState("");
const [audio, setAudio] = useState();
const [animation, setAnimation] = useState(animations.find((a) => a.name === "Idle") ? "Idle" : animations[0].name);
useEffect(() => {
if (!message) {
setAnimation("Idle");
return;
}
setAnimation(message.animation);
setFacialExpression(message.facialExpression);
setLipsync(message.lipsync);
const audio = new Audio("data:audio/mp3;base64," + message.audio);
audio.play();
setAudio(audio);
audio.onended = onMessagePlayed;
}, [message]);
const lerpMorphTarget = (target, value, speed = 0.1) => {
scene.traverse((child) => {
if (child.isSkinnedMesh && child.morphTargetDictionary) {
const index = child.morphTargetDictionary[target];
if (index === undefined || child.morphTargetInfluences[index] === undefined) {
return;
}
child.morphTargetInfluences[index] = THREE.MathUtils.lerp(child.morphTargetInfluences[index], value, speed);
}
});
};
useFrame(() => {
const appliedMorphTargets = [];
if (message && lipsync) {
const currentAudioTime = audio.currentTime;
for (let i = 0; i < lipsync.mouthCues.length; i++) {
const mouthCue = lipsync.mouthCues[i];
if (currentAudioTime >= mouthCue.start && currentAudioTime <= mouthCue.end) {
appliedMorphTargets.push(visemesMapping[mouthCue.value]);
lerpMorphTarget(visemesMapping[mouthCue.value], 1, 0.2);
break;
}
}
}
Object.values(visemesMapping).forEach((value) => {
if (appliedMorphTargets.includes(value)) {
return;
}
lerpMorphTarget(value, 0, 0.1);
});
});
// código omitido por simplicidad
En el fragmento de código proporcionado, actualizamos el componente React, Avatar.jsx, que representa un avatar animado. Aquí hay una explicación detallada de lo que hace cada parte del código:
- Se importan los módulos y recursos necesarios:
useSpeech: Un hook personalizado que proporciona acceso al mensaje actual que se está reproduciendo.facialExpressions: Un módulo que contiene expresiones faciales predefinidas para el avatar.visemesMapping: Un módulo que mapea visemas a objetivos morfológicos del avatar.morphTargets: Un módulo que define los objetivos morfológicos del avatar para diferentes expresiones y movimientos.
- Dentro del componente
Avatar, el resultado deuseSpeechse desestructura enmessageyonMessagePlayed, dondemessagecontiene información sobre el mensaje actual que se está reproduciendo, como texto, expresión facial, animación, audio y metadatos de sincronización labial. - Los estados
lipsync,facialExpression,audioyanimationse inicializan usandouseState. Estos estados almacenan los metadatos de sincronización labial, la expresión facial actual, el objeto de audio del mensaje y la animación actual del avatar. - Se utiliza
useEffectpara realizar acciones cada vez que cambia el mensaje. La animación del avatar se establece en "Idle" si no hay mensaje. De lo contrario, los estados se actualizan con la información del mensaje, se crea un objeto de audio y se reproduce el audio del mensaje. Además, se establece un eventoonendeden el audio para ejecutaronMessagePlayedcuando termina el audio del mensaje. - Se define la función
lerpMorphTargetpara suavizar las transiciones entre los objetivos morfológicos del avatar. - Se utiliza
useFramepara realizar acciones en cada fotograma de animación. En este caso, se calculan y aplican los visemas correspondientes para el audio del mensaje actual. Se itera a través del array "mouthCues" en los metadatos de sincronización labial para determinar el visema activo basado en el tiempo de reproducción de audio actual. Posteriormente, se suavizan las transiciones entre los visemas aplicados y no aplicados.
En resumen, esta actualización del componente Avatar asegura una sincronización precisa entre la animación labial del avatar y el audio del mensaje hablado, proporcionando una experiencia de usuario más realista e inmersiva. ¡Así, hemos terminado de construir nuestro avatar de IA! Si deseas el código completo de esta publicación, puedes encontrarlo aquí.
Conclusión
Después de construir nuestro avatar de IA, podemos concluir que:
La tecnología mejorada de avatares impulsada por LLMs tiene el potencial de crear aplicaciones más interactivas y atractivas para los usuarios.
Minimizar los tiempos de respuesta es un área crítica de mejora en los avatares de IA. Los procesos involucrados en la transcripción de audio, su procesamiento, la generación de respuestas, su conversión en audio y la identificación de visemas para las expresiones faciales a menudo introducen una alta latencia e impactan en la fluidez de la interacción entre humanos y avatares de IA. Explorar técnicas avanzadas como el procesamiento paralelo y el almacenamiento en caché de respuestas anticipatorias puede proporcionar ideas para mejorar la interactividad y la experiencia general del usuario.
En resumen, los avatares de IA están aquí para quedarse, ya que un mercado en rápido crecimiento valorado en varios miles de millones de dólares está explorando su potencial en los sectores de la educación, los videojuegos y el servicio al cliente. Como hemos aprendido a través de este tutorial, estos avatares similares a humanos prometen transformar nuestras interacciones con las computadoras. En el futuro, esperamos ver avances aún más emocionantes y sofisticados a medida que continuamos desarrollando estas tecnologías.
Finalmente, si hay algún error, omisión o inexactitud en este artículo, no dudes en contactarnos a través del siguiente canal de Discord: Math & Code.
Referencias
Footnotes
Ver UneeQ, Wikipedia, Quantum Capture, Unreal Engine, ATRYTONE, Synthesia para más información sobre Humanos Digitales o Avatares de IA. ↩
Ver How ChatGPT, Bard and other LLMs are signalling an evolution for AI digital humans. ↩
